








CVPR 2022 | SparseInst: 基于稀疏实例激活图的实时实例分割框架
2022/04/29


简介
本文提出了一个基于稀疏实例激活图(Sparse Instance Activation Maps)的实时实例分割框架SparseInst。相比于广泛使用的密集型检测分割方法或者先检测后分割(detect then segment)方法,SparseInst利用一系列稀疏的实例激活图来高亮出物体所在的区域,并通过简单的矩阵乘法得到每个实例的特征,之后利用每个实例的特征进行分类和分割,SparseInst无需复杂的后处理步骤,如NMS和Top-K。在这一种新的范式下,SparseInst在MS-COCO数据集实例分割任务上取得了37.9 AP以及40 FPS的推理速度(NVIDIA 2080Ti),如下图所示,在速度和精度的平衡上,SparseInst显著优于其他方法,使用更大的输入尺寸和更复杂的主干网络,SparseInst依旧能够取得非常快的推理速度。

图1 Speed-and-Accuracy trade-off
动机
1.1 物体表征
在通用物体检测以及实例分割领域中,大多数方法主要采用两种物体表征方式:(1)基于anchor (center) 的表征和(2)基于区域框的物体表征,如图2所示,其中基于anchor的物体表征将每一个像素作为一个物体的样本,通过密集预测(dense prediction)的方式实现物体检测,其主要应用于单阶段监测算法,如RetinaNet[1] 和FCOS[2] ,而基于区域框的表征将整个物体框内的特征作为物体的表征,其主要应用于两阶段算法的第二阶段,如Faster R-CNN[3] 及其各种改进方法。

图2 物体表征方式
这两种表征方法在目前物体检测和实例分割问题中取得了非常大的突破,然而,我们认为这两种方法仍然存在一些问题。其中,基于anchor的表征方式依赖于密集的像素级预测,而单个像素表征缺乏物体的整体上下文信息,由于匹配策略,一些物体之外的像素点会被标注为正样本,此外,密集anchor也会产生大量的物体预测,不仅产生冗余的计算,也会对后处理造成一些压力;而基于区域框的物体表征通常会结合RoI-Align提取区域框特征,然而区域框内往往含有很多背景信息或者其他物体的信息,此外,这类方法通常需要RPN进行区域框的生成,整体框架会更加复杂。
对此,我们也经常在思考,究竟怎样一种物体表征方式,能够更加灵活自适应的表征物体,并且不依赖于密集预测和复杂的框架。
1.2 实例激活图
在视觉弱监督学习领域,我们经常会提到CAM[4] (Class Activation Maps,类激活图),即在提供图像级别类别标注信息,模型利用这种弱监督信号找到每个类别的激活响应区域。CAM能够为我们找到某一类别在图像中具有区分性的区域,并提供了定位信息。基于此,我们进一步拓展CAM,定义了一组IAM (Instance Activation Maps, 实例激活图),用来区分不同的实例,即用激活图来表征单个物体,不同的物体使用不同的激活图进行表示,如图2-(c)所示。IAM可以自适应地对单个物体具有区分性的区域进行高亮,得到更加灵活的感兴趣区域。由于IAM采用自适应的区域表征,其能够捕捉到和物体相关的一些关键上下文信息,此外,IAM不依赖于像素级别的密集预测,可以采用一组稀疏的IAM来高亮出图像所有物体。在bipartite matching的匹配策略下,IAM可以实现和标注物体一一对应,实现无需后处理的端到端框架。
方法
2.1 实例激活图
IAM旨在于自适应地激活物体的感兴趣的区域,之后便可以聚合激活区域的特征 (通过加权求和方式),得到单个物体的特征表示,如图 3-(a) 所示。此外,本文进一步拓展IAM到Group-IAM,即显式地对单个物体激活多个区域,如图 3-(b) 所示,提取每一个区域的特征并聚合成一个新的物体特征表示,相比于IAM,Group-IAM能够捕捉到更多区域,得到更强的物体特征表示。

图3 实例激活图
对于物体检测和实例分割,我们只需要定义一组稀疏的IAM,如100个实例激活图,每个/组IAM负责一个物体,基于这种简单表示,本方法不再需要设计复杂的匹配策略、不在需要密集预测、不在需要复杂的后处理,如NMS和排序,同样,凭借IAM的自适应特性,本方法不需要复杂的多层预测来缓解遮挡和密集场景带来的问题,整个物体检测和实例分割的流程也能因此简化很多,推理速度也随之大幅提升。
2.2 整体框架
SparseInst是一个全卷积的框架,包含主干网络、多尺度特征编码器以及基于IAM的解码器,如图4所示。其中编码器采用类似于FPN的多层特征融合,并且引入了PPM (Pyramid Pooling Module) 来扩大特征感受野,编码器输出下采样为原图1/8的单尺度特征。
解码器包含两分支,其中一分支 (实例分支) 负责IAM的预测,IAM和Group-IAM分别采用简单的3x3卷积和Group 3x3卷积实现,并使用sigmoid实现归一化,区域特征提取采用的矩阵乘法,在通过IAM得到的物体表征 后,我们直接利用全连接网络预测了物体的类别,物体的置信度得分(分割IoU相关),以及分割的参数(kernel);另一个分支 (分割分支) 实现了分割特征M的提取,结合每个物体的分割参数,利用矩阵乘法即可得到每一个物体对应的分割。
模型最终的输出即为N个物体的分类、置信度分数以及相应的分割,SparseInst不需要复杂的后处理步骤,不依赖于NMS和Top-K进行冗余框的筛选。
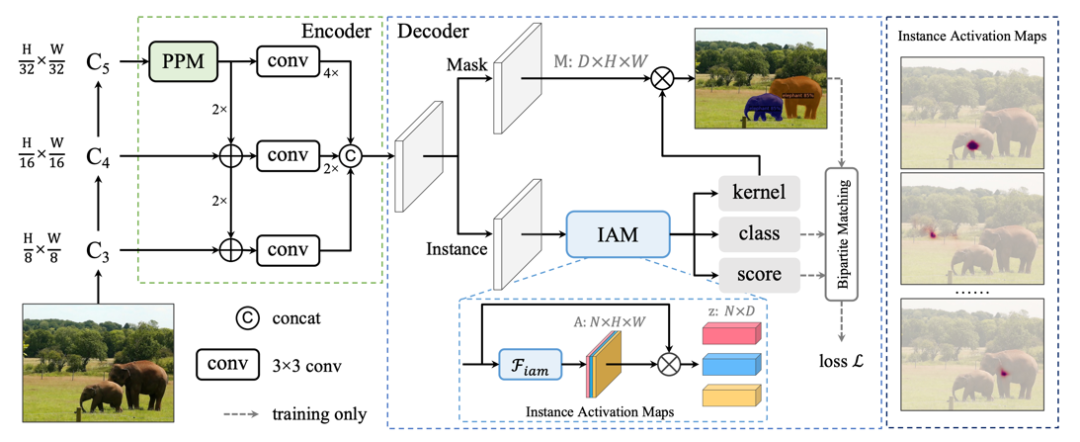
图4 SparseInst整体框架
SparseInst凭借稀疏的IAM高亮出图像中所含有物体,极大程度减少了冗余的计算,并通过单尺度预测简单的模型结构和后处理步骤实现了更快的推理速度。
2.3 模型训练
SparseInst采用DETR[5] 提出的Hungarian algorithm进行预测和真实标注的匹配,每一个真实物体都会和一个IAM进行匹配。首先,我们针对实例分割定义了匹配系数:

其中p是物体对应类别的分数,DICE用来衡量预测结果的分割和真实标注的分割之间的相似性,计算出每个预测物体和真实标注之间的匹配系数后,我们采用Hungarian algorithm寻找出了最佳的一个匹配,并利用匹配关系,计算出训练损失。也正是利用这种一对一的匹配关系,IAM能够实现对单个物体的响应,找到每个物体最具区分性的区域。
实验结果
3.1 COCO实例分割结果对比
如表1所示,SparseInst在精度更高的情况下,取得了了更快的推理速度,即便采用了更大图像输入,或者采用了更加复杂的主干网络,SparseInst依旧能够实现高速的推理,在速度和精度的平衡下,SparseInst取得了目前的SOTA结果。

3.2 IAM的实验探究
在表2中,我们进一步验证了不同IAM的效果,其中使用1x1卷积替代3x3卷积会带来显著的性能下降,3x3卷积相对于1x1卷积能够感知局部区域。使用softmax替换sigmoid会带来小幅度的性能下降,对于Group-IAM,在使用4-group的时候,整体提升了0.7AP,时间开销上没有明显的变化。在原文中,我们深入探究了Cross Attention和IAM的区别与联系,相比于Transformer方法[5] 采用object queries和Cross Attention来表征物体,IAM能够利用局部区域的一些上下文信息和一些物体的结构信息,进而,性能也会优于Cross Attention。

表2 IAM的探究实验
注:更多验证和分析实验,详情见原文实验部分
3.3 推理速度分析
表3分析了SparseInst不同模块的时间占比,主干网络在推理中占据了50%以上的时间,而后处理仅2 ms,但却占据了10%的时间,而最快的NMS算法也至少需要2ms。

表3 推理速度模块级别分析
可视化结果
4.1 IAM可视化结果
图5展示了不同IAM在MS COCO验证集的5000张图像上的响应区域,我们发现,不同的IAM会聚焦在不同的位置区域,即负责激活一些固定位置的区域。

图5 12组实例激活图统计结果
4.2 IAM与分割可视化结果
图6展示了IAM与其对应分割的可视化结果,IAM会自适应激活一些“感兴趣区域”(落在了物体不同的区域),并聚合这些感兴趣区域的特征实现进行分类分割。

图6 实例激活图与对应的分割结果
4.3 实例分割可视化结果
图7展示了SparseInst在MS-COCO上的可视化结果,SparseInst能够有效区分密集场景/遮挡的物体,并且获得精细的分割结果。

图7 SparseInst的可视化结果
结论和未来展望
我们提出使用一种稀疏的实例激活图作为物体表征,相比anchor-based或者box-based的方法,实例激活图能够更加自适应的激活物体的感兴趣区域,提供更多的上下文信息。对于每一个输入,本方法采用一组IAM即可检测分割出所有的物体,而不在需要多尺度和密集预测。基于IAM的实例分割框架SparseInst也取得了极快的推理速度。
在将来的工作中,我们将继续拓展SparseInst,让IAM更加通用和高效,并拓展SparseInst到全景分割,此外,我们将持续提供更多的优化和部署支持,推进算法框架的落地应用。
参考文献
[1] Lin et.al. Focal Loss for Dense Object Detection. ICCV 2017.
[2] Tian et.al. FCOS: Fully Convolutional One-Stage Object Detection. ICCV 2019.
[3] Ren et.al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE TPAMI 2017.
[4] Zhou et.al. Learning Deep Features for Discriminative Localization. CVPR 2016.
[5] Carion et.la. End-to-End Object Detection with Transformers. ECCV 2020.
分享文章







欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


