








好算法更要配好用的芯片 —— 基于LSS范式的BEV感知算法优化部署详解
2023/12/29

地平线征程®5
地平线征程5是专为高阶智能驾驶打造的智能计算方案,搭载地平线第三代架构BPU--贝叶斯(Bayes),算力可达128TOPS,是率先实现前装量产的国产百TOPS级智能计算方案。基于征程5开发的高等级自动驾驶方案可实现ADAS功能、高速导航智能驾驶、城区导航智能驾驶和智慧泊车的全场景覆盖。针对自动驾驶实际工况,Bayes结合突破性的AI加速计算技术,通过灵活配置的访存计算,极大的优化内存占用及访存,将并行计算发挥到极致! |
简介
BEV即Bird's Eye View(鸟瞰视图)是一种从空中俯视场景的视角。由多张不同视角采集的图像通过不同的空间转换方式形成,如下图所示,左侧为6张不同位置的相机采集的图像,右侧为转换的BEV图像。

BEV感知模型指的是直接输出BEV坐标系下的感知结果,如动静态检测目标,车道线,路面标识等。BEV坐标系好处是:
1. 成本低。相比3D点云的方式来补充3维信息,纯视觉方案的成本更低;
2. 可以直接给到下游任务,例如预测和规划;
3. 可以在模型中融合各视角的特征,提升感知效果;
4. 可以更好的和各类传感器进行融合。
对于下游的预测和规控任务而言,需要的是3D的目标,因此在传统的自动驾驶方案中,2D的感知推理结果需要通过复杂的后处理去解决3D坐标提升的问题。而BEV感知模型是更接近于一种端到端的解决方案。
当前主要的BEV 转换方式为以下三种:
• IPM-based:基于地面平坦假设的逆透视映射方式,技术简单成本低,但是对上下坡情况拟合效果不好。
• LSS-based:通过显示的深度估计方式构建三维视锥点云特征,也是较常用的转换方式。
• Transformer-based:用transformer机制学习3D query和2D 图像特征之间的关系来建模。部署时global attention的计算量较大, 需要考虑端侧运行时对性能的影响。
在实际部署时,需要考虑算法的端侧性能。地平线的参考算法目前已赋能多家客户实现BEV感知算法在征程5上的部署和开发,多家客户已实现BEV demo开发。本文以LSS范式的BEV感知算法为例,介绍地平线提供的参考算法如何在公版的基础上做算法在征程5芯片的适配和模型的优化。
整体框架

BEV 感知架构
BEV系列的模型使用多视图的当前帧的6个RGB图像作为输入。输出是目标的3D Box和BEV分割结果。多视角图像首先使用2D主干获取2D特征。然后投影到3D BEV视角。接着对BEV feature 编码获取BEV特征。最后,接上任务特定的head,输出多任务结果。模型主要包括以下部分:
Part1—2D Image Encoder:图像特征提取层。使用2D主干网络(efficientnet)和FastSCNN输出不同分辨率的特征图。返回最后一层--上采样至1/16原图大小层,用于下一步投影至3D BEV坐标系中;
Part2—View transformer:采用不同的转换方式完成图像特征到BEV 3D特征的转换;
Part3—BEV transforms:对BEV特征做数据增强,仅发生在训练阶段;
Part4—3D BEV Encoder:BEV特征提取层;
Part5—BEV Decoder:分为Detection Head和Segmentation Head。
LSS方案
公版的LSS方案如下:
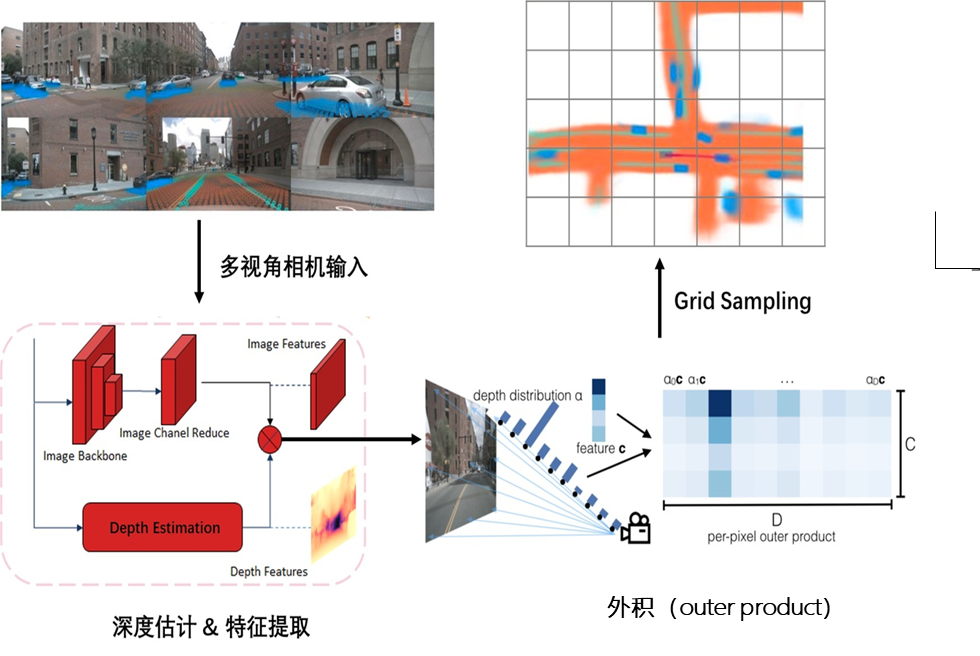
公版的LSS方案分为3个部分:
1. 将图像从2d平面提升到3d空间,生成3d视锥(frustum)点云,并对点云上所有的点预测context特征,生成context特征点云;
2. 对视锥点云和context特征点云进行 “Splat” 操作,在BEV网格中构建BEV特征;
3. BEV特征后,可通过“Shooting”完成特定的下游任务,比如Motion Planning。
模型部署分析
在部署之前,需要对公版模型做部署分析,避免模型中有BPU无法支持的算子和某些对性能影响较大的算子。对于无法支持的算子,需要做替换;对于影响性能的算子需要做优化。同时为了达到更好的精度会增加训练策略的优化和量化策略的优化。本章节先对公版模型做部署分析,最后给出地平线的优化方式。
问题1 大尺寸运算导致性能瓶颈
由于深度特征的增加,feature的维度是高于4维的,考虑到transpose算子的耗时问题和部署问题,LSS方案中会存在维度的折叠,对feature做view和H维度的折叠。对应的操作为:depth_feature会做view和Dim、H和W的折叠。维度折叠会导致feature的维度变大,在生成视锥点云时,其涉及的操作mul操作的输入也就增大了,在做部署时会导致DDR带宽问题。因此公版的步骤1中的大尺寸算子计算需要做对应的优化。
问题2 BEVpooling的索引操作支持问题
公版在做2D到3D转换时,从图像空间的index映射到BEV空间的index,相同的BEV空间index相加后再赋值到BEV tensor上,即公版的步骤二。考虑到征程5对索引操作无法支持,因此该操作在部署时需要做替换。
问题3 分割头粒度太粗
地平线提供的是多任务的BEV感知算法,对于多任务模型来说不同的任务需要特定的范围和粒度,特别是对于分割模型来说,分割的目标的粒度较小,因此相比于检测任务来说feature需要细化,即用更大的分辨率来表示。
问题4 grid 量化精度误差问题
对于依赖相机内外参的模型来说,转换时的点坐标极其重要,因此需要保障该部分的精度。同时grid的表示范围需要使用更大比特位的量化。
针对以上4个问题,本章节会介绍该部分在征程5的实现方式使其可以在板端部署并高速运行。
性能优化
mul的性能优化
为了减少大量的transpose操作和优化mul算子的耗时问题, 我们选择把深度和 feature 分别做grid_sample后执行mul操作,具体操作如下:
Python
#depth B, N, D,H, W
depth = tensor(B,N,D,H,W)
feat = tensor(B,N,C,H,W)
#depth B, 1, N *D, H*W
depth = depth.view(B, 1, N*D, H*W)
#feat -> B,C,N,H,W-> B, C, N*H, W
feat = feat.permute(0, 2, 1, 3, 4).view(B, C, N*H, W)
for i in range(self.num_points):
homo_feat = self.grid_sample(
feat,
fpoints[i * B : (i + 1) * B], )
homo_dfeat = self.dgrid_sample(
dfeat,
dpoints[i * B : (i + 1) * B],
)
homo_feat = self.floatFs.mul(homo_feat, homo_dfeat)
homo_feats.append(homo_feat)
mul操作的计算量大幅减少,性能上提升4~5倍!
BEV_pooling部署优化
使用grid_sample代替公版的3D空间转换。即从原来的前向wrap-从图像空间特征转换到BEV空间特征,改为从BEV空间拉取图像空间特征。
1. 公版实现:
a. 通过一个深度估计变成6D的tensor
Python
volume = depth.unsqueeze(1) * cvt_feature.unsqueeze(2)
volume = volume.view(B, N, volume_channel_index[-1], self.D, H, W)
volume = volume.permute(0, 1, 3, 4, 5, 2)
b. 从图像空间的index映射到BEV空间的index,相同的BEV空间index相加后再赋值到BEV tensor上
Python
def voxel_pooling(self, geom_feats, x):
...
# flatten x
x = x.reshape(Nprime, C)
# flatten indices
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long()
geom_feats = geom_feats.view(Nprime, 3)
...
# filter out points that are outside box
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < nx[0]) \
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < nx[1]) \
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < nx[2])
geom_feats = geom_feats[kept]
x = x[kept]
...
# argsort and get tensors from the same voxel next to each other
ranks = geom_feats[:, 0] * (nx[1] * nx[2] * B) \
+ geom_feats[:, 1] * (nx[2] * B) \
+ geom_feats[:, 2] * B \
+ geom_feats[:, 3]
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts]
...
return final
2. 地平线实现:
使用grid_sample代替公版的3D空间转换。grid_sample为采样算子,通过输入图像特征和2D点坐标grid,完成图像特征到BEV特征的转换,其工作原理见下图。
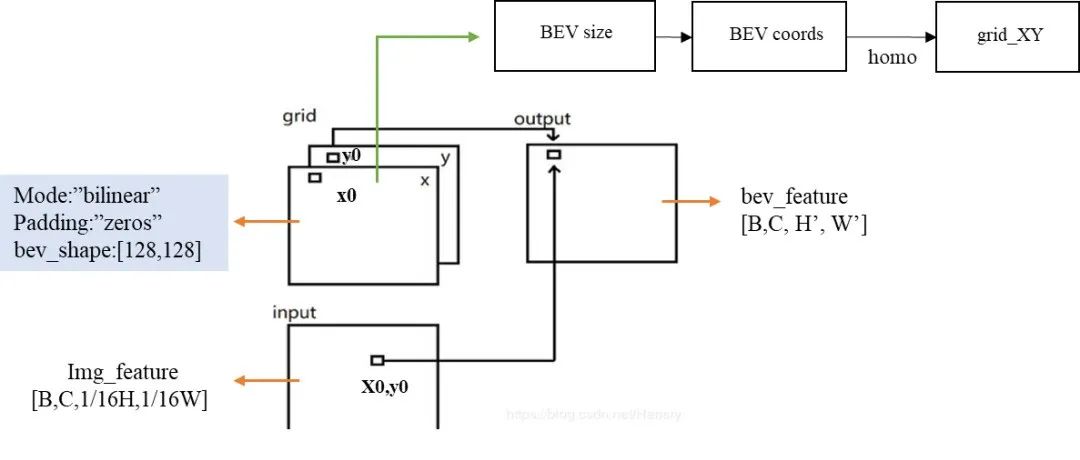
Grid_Samples 原理图
horizon_plugin_pytorch提供的grid_sample算子和公版输入略有差异,地平线已支持公版的grid_sample算子。
由于该转换方式是前向映射,前向映射会产生的BEV index并不均匀,最多的一个voxel有100多个点,最少有效点为0。我们在提供的源代码中使用了每个voxel使用了10个点,如果想要提升精度可以考虑增加每个voxel的有效点。
Python
#num_point为10
for i in range(self.num_points):
homo_feat = self.grid_sample(
feat,
fpoints[i * B : (i + 1) * B],
)
homo_dfeat = self.dgrid_sample(
dfeat,
dpoints[i * B : (i + 1) * B],
)
homo_feat = self.floatFs.mul(homo_feat, homo_dfeat)
homo_feats.append(homo_feat)
精度优化
多任务模型的精度优化
参考BEVerse模型对多任务根据不同粒度进行细化,在分割头做解码之前,将BEV feature的分辨率增大,map size为[200,400],实现上由grid_sample完成。

Python
#init map module
if (self.bev_size and self.task_size and self.task_size != self.bev_size):
self.grid_sample = hnn.GridSample(
mode="bilinear",
padding_mode="zeros",
)
#decoder module forward
def forward(self, feats: Tensor, meta: Dict) -> Any:
feat = feats[self.task_feat_index]
if hasattr(self, "grid_sample"):
batch_size = feat.shape[0]
new_coords = self.new_coords.repeat(batch_size, 1, 1, 1)
feat = self.grid_sample(feat, self.quant_stub(new_coords))
feat = [feat]
pred = self.head(feat)
return self._post_process(meta, pred)
浮点模型精度的优化
在浮点模型的训练上,使用数据增强来增强模型的泛化能力,通过尝试不同的增强方式,最终选取BEVRotate方式对输入数据做transform。相比于未做数据增强的浮点模型mAP提升1.5个点,NDS提升0.6个点。详细实验记录见实验结果章节。

该实验结果为中间结果,非最终精度数据
量化精度的优化
BEV_LSS的量化训练采用horizon_plugin_pytorch的Calibration方式来实现的,通过插入伪量化节点对多个batch的校准数据基于数据分布特征来计算量化系数,从而达到模型的量化。BEV_LSS模型无需QAT训练就可以达到和浮点相当的精度。
除了量化方式上的优化,地平线对输入的grid也做了优化,包括了
1. 手动计算scale,使用固定的scale作为grid的量化系数。
Python#fix scaledef get_grid_quant_scale(grid_shape, view_shape): max_coord = max(*grid_shape, *view_shape) coord_bit_num = math.ceil(math.log(max_coord + 1, 2)) coord_shift = 15 - coord_bit_num coord_shift = max(min(coord_shift, 8), 0) grid_quant_scale = 1.0 / (1 << coord_shift) return grid_quant_scale#get grid_quant_scalegrid_quant_scale = get_grid_quant_scale(grid_size, featview_shape)##initself.quant_stub = QuantStub(grid_quant_scale)
2. grid_sample算子的输入支持int16量化,为了保障grid的精度,地平线选择int16量化。
Pythonself.quant_stub.qconfig = qconfig_manager.get_qconfig( activation_qat_qkwargs={"dtype": qint16, "saturate": True}, activation_calibration_qkwargs={"dtype": qint16, "saturate": True},)
基于以上对量化精度的优化后,最终定点精度达到和浮点相当的水平,量化精度达到99.7%!
实验结果
1. 性能和精度数据
数据集 | Nuscenes | |
Input shape | 256x704 | |
backbone | efficientnetb0 | |
bev shape | 128x128 | |
FPS(单核) | 138 | |
latency(ms) | 8.21 | |
分割精度(浮点/定点)iou | divider | 46.55/47.45 |
ped_crossing | 27.91/28.44 | |
Boundary | 47.06/46.03 | |
Others | 85.59/84.49 | |
检测精度(浮点/定点) | NDS | 0.3009/0.3000 |
mAP | 0.2065/0.2066 | |
注:grid_sample的input_feature H,W ∈ [1, 1024] 且 H*W ≤ 720*1024
2. 不同数据增强方式对浮点模型的精度影响。

该实验结果为中间结果,非最终精度数据
3. 地平线征程5部署LSS范式的BEV模型通用建议
• 选用BPU高效支持的算子替换不支持的算子。
• num_point会直接影响性能和精度,可以根据需求做权衡。处于训练速度考虑使用topk选择点,若想要更高的精度可以对点的选择策略做优化。
• grid使用fixed scale来保障量化精度,如超过int8表示范围则开启int16量化,具体见grid量化精度优化章节。
• 对于分辨率较大导致带宽瓶颈或不支持问题,可以拆分为多个计算,缓解带宽压力,保障模型可以顺利编译。
• 对于常量计算(例如:grid计算)编译时可以作为模型的输入,提升模型的运行性能。
总结
本文通过对LSS范式的BEV多任务模型在地平线征程5上量化部署的优化,使得模型在该计算方案上用远低于1%的量化精度损失,得到latency为8.21ms的部署性能,同时,通过LSS范式的BEV模型的部署经验,可以推广到基于该范式的BEV模型的优化中,以便更好的在端侧部署。
附录

算子支持列表

参考算法
版本发布

使用文档
分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


