








开发者说 | UniMM:重新审视多智能体仿真中的混合模型
2025/03/29


• 原文链接:
https://arxiv.org/abs/2501.17015
• 项目主页:
https://longzhong-lin.github.io/unimm-webpage
• 代码仓库:
https://github.com/Longzhong-Lin/UniMM
多智能体仿真
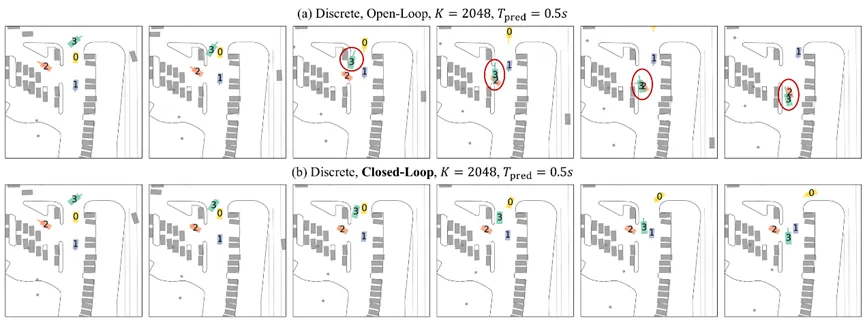
仿真 (Simulation) 是评估自动驾驶系统的重要途径,生成真实的多智能体 (Multi-Agent) 行为是其中的关键。近年来,许多工作采用数据驱动的方法,从真实世界驾驶数据集中学习行为模型 (Behavior Model) 来模仿人类交通参与者。要实现真实的多智能体仿真,主要挑战在于捕捉智能体行为的多模态性 (Multimodality) 和解决模型闭环运行的分布偏移 (Distributional Shifts) 问题。
图表1 多智能体仿真
智能体行为的多模态性在运动预测 (Motion Prediction) 领域得到广泛研究,其中主流方法采用的是混合模型 (Mixture Model) 。由于任务的相似性,不少仿真领域的工作也采用类似的连续混合模型 (Continuous Mixture Model) 来表征智能体行为。最近,受大语言模型的启发,越来越多的研究开始尝试GPT架构的离散模型 (GPT-Like Discrete Model) ,将智能体的轨迹离散化为运动Token并进行NTP (Next-Token Prediction) 训练,在仿真领域展现出了超越连续混合模型的性能优势。
为了缓解模型闭环运行的分布偏移,时间序列建模领域的DaD方法继承在线学习算法DAgger的理论保证,将训练样本中的真值输入替换为自回归模型预测,不过该方法只讨论了单模态 (Unimodal) 模型。TrafficSim将类似方法应用在CVAE行为模型,迭代地将真值轨迹替换为后验 (Posterior) 预测,从而生成闭环样本 (Closed-Loop Sample) 。
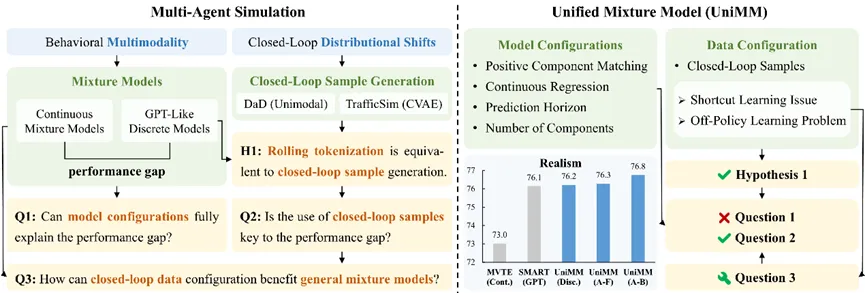
图表2 UniMM研究概述
统一混合模型框架
我们注意到,GPT-Like离散模型本质上是一种混合模型,其中每个混合组分 (Mixture Component) 代表一个离散类别,而运动Token则是各组分对应的锚点 (Anchor) 。因此,本文建立统一的混合模型框架 (Unified Mixture Model, UniMM) ,并从模型和数据两个方面展开研究,探索GPT-Like方法优势的根源,并尝试推广到更一般的混合模型中。
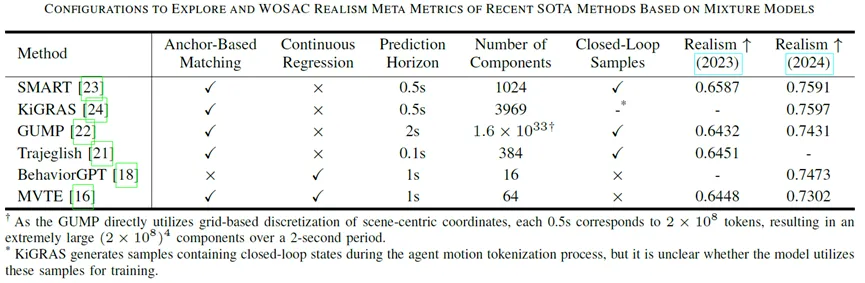
图表3 WOSAC领先方法(可视为混合模型)的配置和指标
“
模型配置
模型方面,我们关注的配置包括:
正组分匹配 (Positive Component Matching) :主流范式为无锚点 (Anchor-Free) 和基于锚点 (Anchor-Based) 匹配。
连续回归 (Continuous Regression) :若Anchor-Based模型将锚点直接作为对应混合组分的预测轨迹,则无需连续回归。
预测时长 (Prediction Horizon) :模型预测轨迹的长度。
混合组分数量 (Number of Components) :混合模型中混合组分的数量。
其中,GPT-Like离散模型采用Anchor-Based正组分匹配且不具备连续回归,通常使用大量混合组分且预测时长较短。后面的实验表明:模型配置的差别并不能完全解释连续混合模型和GPT-Like离散模型之间的性能差距。采用与GPT-Like方法完全不同的模型配置,也可以达到同样优秀的仿真性能。

图表4 主流的正组分匹配范式
“
数据配置
数据方面,我们借鉴DaD和TrafficSim的设计理念,提出了适用于一般混合模型的闭环样本生成方法。具体地,我们基于原始开环样本自回归地运行模型,将样本中的真值输入状态替换为与之匹配的后验模型预测(我们称之为后验规划)。生成的闭环样本在尽量接近真值的同时,将模型预测引入到样本输入中,使训练期间模型见到的状态更接近在闭环仿真中遇到的状态,从而缓解分布偏移。

图表5 闭环样本生成
对于GPT-Like离散模型,我们证明:上述闭环样本生成方法等价于采用滚动匹配 (Rolling Matching) 的智能体运动Tokenization。后面的实验表明:使用闭环样本进行训练是生成逼真多智能体行为的关键。进一步地,为了让闭环样本能够惠及更广泛的混合模型,我们识别并解决了Shortcut Learning和Off-Policy Learning问题。
实验
“
网络架构
实验中使用的网络架构包含场景编码器 (Context Encoder) 和运动解码器 (Motion Decoder) 。场景编码器能够并行处理多智能体在多个时间上的信息;运动解码器生成特定智能体从指定时间开始的多模态未来轨迹。特别地,对于带连续回归的Anchor-Based模型,我们的解码器先对锚点打分、再生成所选取组分对应的轨迹,使得其能够像离散模型一样高效地增加混合组分的数量。
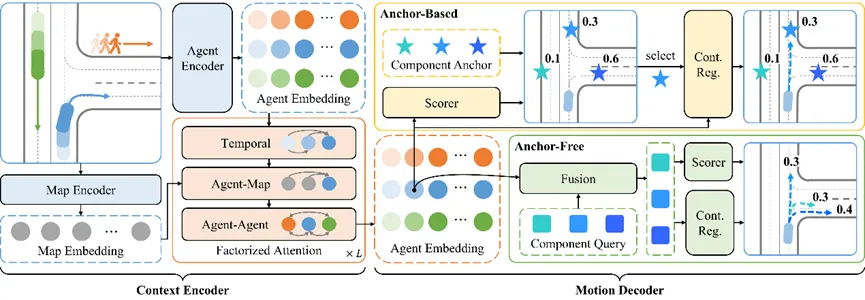
图表6 混合模型网络结构
“
采用开环样本训练
我们首先探索不同预测时长和混合组分数量下的Anchor-Free和Anchor-Based模型。在这里,我们采用开环样本训练来保证数据的一致性,从而更好地体现上述模型配置的影响。
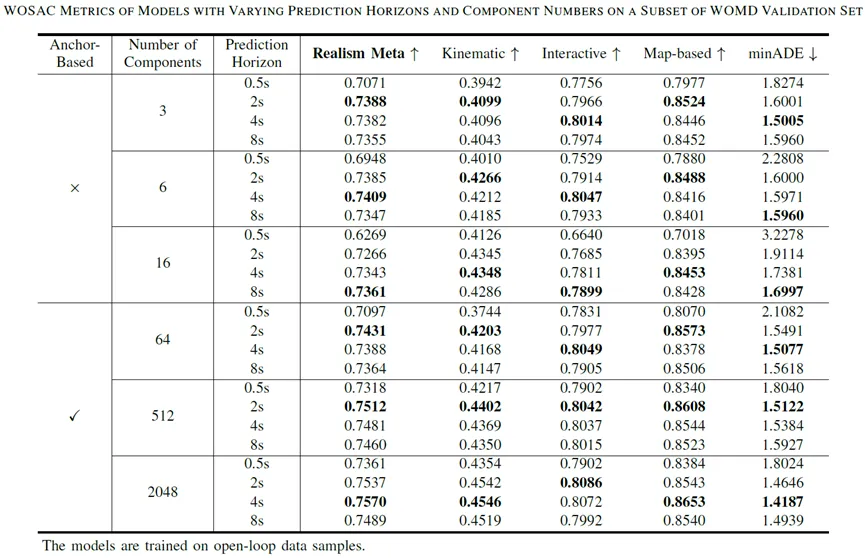
图表7 采用开环样本训练
预测时长:
更大的预测时长 (Prediction Horizon) 带来的额外监督信号是有效的。
过大的预测时长使模型更关注于远期预测的优化,由于仿真仅会利用模型预测的前面一小段,所以这并不利于提升仿真的效果。

图表8 不同预测时长的WOSAC指标
混合组分数量:
增加混合组分的数量确实能够提升模型对复杂分布的表征能力。
较多数量的混合组分可能会阻碍Anchor-Free模型挑选出合理轨迹,从而影响其在仿真中的表现。
Anchor-Based模型持续受益于混合组分数量的增长。

图表9 不同混合组分数量下的最优WOSAC指标
“
采用闭环样本训练
接下来展开对数据配置的研究,我们从开环样本实验中表现最佳的模型配置出发,从而凸显闭环样本的作用。
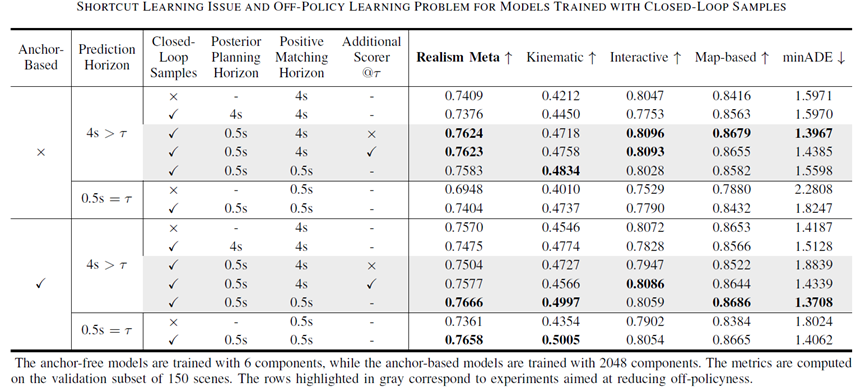
图表10 采用闭环样本训练
Shortcut Learning问题:
生成闭环样本时,若后验策略的规划时长 (Posterior Planning Horizon) 超过其重规划间隔,模型会学习到捷径,损害时空交互推理能力。
Off-Policy Learning问题:
若训练策略的正组分匹配时长 (Positive Matching Horizon) 和样本生成策略的后验规划时长 (Posterior Planning Horizon) 不一致,则其导致的Off-Policy Learning问题会阻碍闭环样本发挥作用。
对于Anchor-Free模型,Off-Policy Learning问题的影响没那么严重,这可能是因为它们的性能更依赖于各混合组分的灵活预测,而不是对混合组分的挑选。
对齐训练策略和样本生成策略的组分选择Horizon可以有效缓解Off-Policy Learning问题,特别是对于十分依赖其混合组分选择的Anchor-Based模型。

图表11 近似后验策略(左)和连续回归(右)
近似后验策略:
我们为Anchor-Based模型设计了近似后验策略,将后验组分对应的锚点直接作为执行规划,可以在显著减少训练时间的同时,达到相当的仿真性能。
连续回归:
主流离散模型成功的关键在于闭环样本的使用。
连续回归 (Continuous Regression) 带来的灵活性对于模型性能是有增益的,同时其并不需要显著增加计算开销。
“
Benchmark结果
基于上述探索,我们提交了UniMM框架下的各种变体(包括离散和连续、Anchor-Free和Anchor-Based),均在Waymo Open Sim Agents Challenge (WOSAC) 中展现了SOTA性能。由此证明了:
模型配置的差别并不能完全解释之前的连续混合模型和GPT-Like离散模型之间的性能差距。
仿真性能的关键在于闭环样本的使用,采用与主流离散方法不同的模型配置也能生成逼真的行为。
通过解决Shortcut Learning和Off-Policy Learning问题,闭环样本能够使广泛的混合模型受益,尤其是具有更大预测时长的模型。

总结与展望
本研究首先建立了多智能体仿真的统一混合模型框架,并针对该框架下的模型配置(正组分匹配、连续回归、预测时长、混合组分数量)和数据配置(闭环样本生成方法)进行深入的分析与实验。我们通过最优的网络结构设计、参数配置和训练方式得到的模型仅需4M参数量的情况下,在Waymo Open Sim Agents Challenge达到了SOTA的性能。基于以上多智能体仿真的模型优化分析和实验结论,我们今后会进一步去探索自动驾驶的运动规划问题。

分享文章




欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


