








CVPR 2025|GoalFlow:目标点驱动,解锁端到端生成式策略新未来
2025/03/17


• 论文链接:
https://arxiv.org/abs/2503.05689
• 项目链接:
https://github.com/YvanYin/GoalFlow
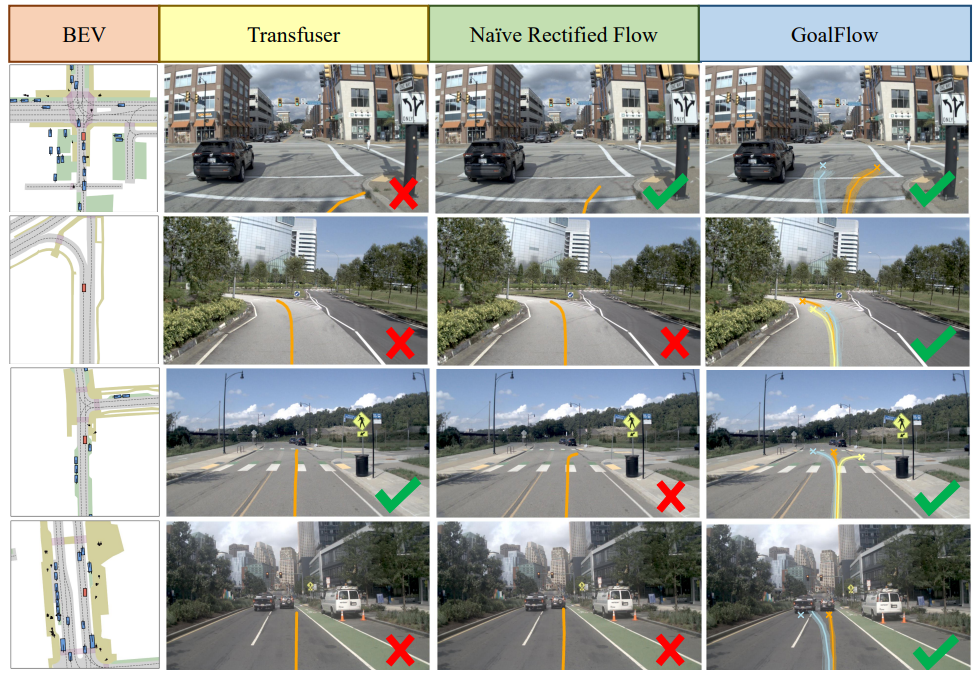




概述
自动驾驶轨迹规划往往采用直接回归轨迹的方法,这种方式虽在测试中能取得不错的性能,可直接输出当前场景下最有可能的轨迹或控制,但它难以对自动驾驶场景中常见的多模态动作分布进行有效建模。在实际驾驶场景里,往往不存在唯一的最优决策,不同的路况、交通标志以及其他道路使用者的行为等,都可能导致车辆存在多种合理的行驶轨迹选择,而回归模型在处理这种多模态特性时显得力不从心。为了解决这个问题,我们提出了一种基于goal point的生成式方法GoalFlow,通过使用goal point这种强引导信息来引导生成式模型生成安全、高质量、多模态的规划轨迹。我们的方法在公开数据集Navsim综合分数大幅领先其他方法。同时,通过Flow Matching对轨迹分布进行建模仅用一步降噪即可实现优秀的推理性能。
GoalFlow解决的问题
当前生成多模态候选轨迹的方法主要由两种方式:一种是在回归轨迹的基础上添加不同的引导信息,例如左右转等。另一种是通过扩散模型这种连续建模的方式通过不断加噪和去噪来生成众多的轨迹。这两种方式都很难达到理想的效果。前者容易发生轨迹的坍缩,引导出的轨迹非常相似。后者容易生成高度发散的轨迹,这为挑选轨迹增加了难度。为此,GoalFlow主要思考如何探索其他可行道路来实现高质量的候选轨迹生成。
“
如何应对生成式模型轨迹过于发散的情况
相比生成众多发散的候选轨迹,从中挑选出来一条最优的作为输出是更加困难的事情。我们希望通过降低轨迹的发散程度来减轻轨迹打分器的压力。而其中,使用什么样的信息来对轨迹进行约束是最重要的。我们发现,相比于dense的图像或者BEV特征,扩散模型更喜欢sparse的信息。于是,我们采用一段轨迹中最重要的点end point作为goal point来对轨迹进行约束,使得车辆能行驶到goal point。
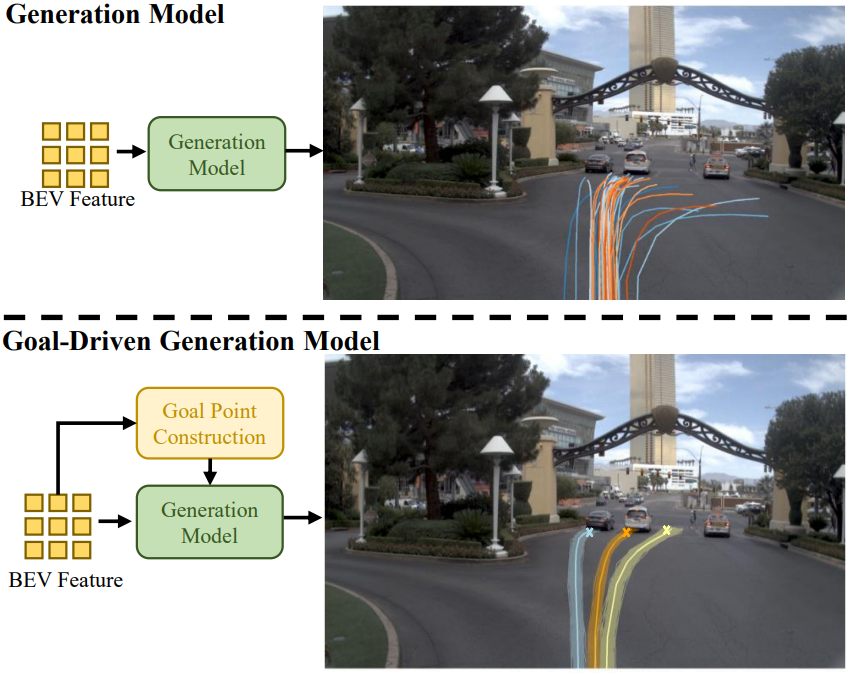
“
如何构造goal point
goal point在自动驾驶中并不是个新事物,业务中往往可以使用车道信息来预测goal point或者使用直接将导航作为goal point。但是车道信息往往需要昂贵的高精地图,而导航往往并不表示车辆在未来几秒后的精确信息。其他学术上的方法也有map-free的用网格将空间划分若干单元来进行预测,这种方式又没有充分考虑到goal point自身的分布特性。在调研众多方法后,我们根据VADv2的做法,首先将轨迹的末端点进行聚类得到goal point的分布特性后,再从不同角度对goal point进行评估。
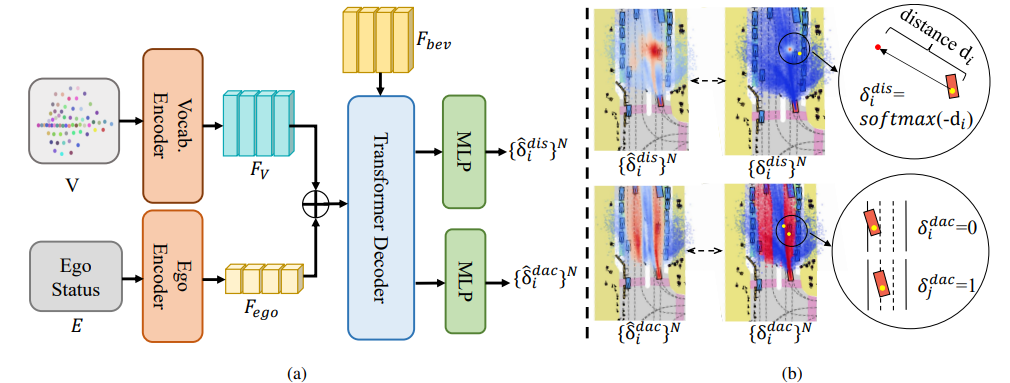
“
如何平衡生成准确轨迹和多模态轨迹
输入给生成模型的信息包括两种,一种是goal point来对轨迹进行约束和引导,一种是场景信息的BEV特征。前者对轨迹的要求是生成指向goal point的轨迹,后者是生成当前情况下最有可能的轨迹。为了平衡这两种需求,我们主要进行了训练策略上的不同测试。具体来说,我们会对这两种信息分别进行类型编码,在训练过程中采用Classifier-Free Guidance策略,随机drop掉这两种特征。训练时condition输入包括三类:无condition,场景信息作为condition以及场景信息和goal point作为condition。
GoalFlow框架
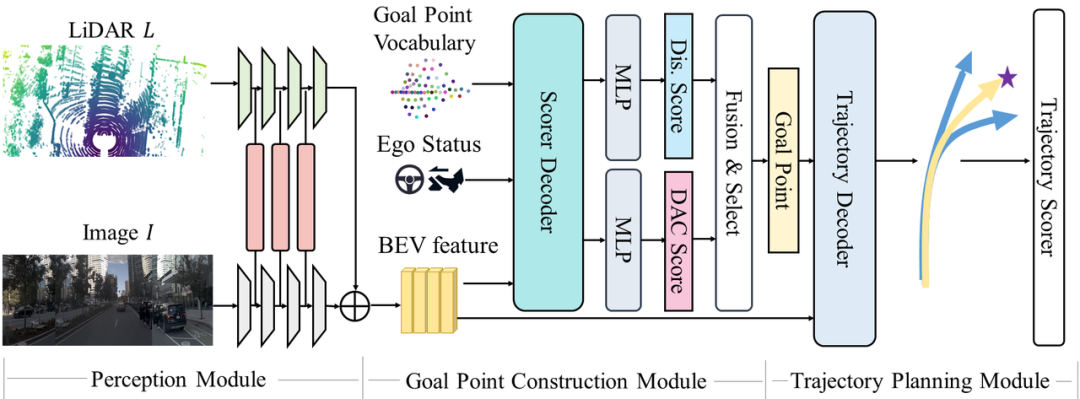
核心思路:引入goal point作为引导信息,通过建立dense的goal point词汇表和新颖评分机制挑选最优goal point,再由goal point和场景信息作为condition,交给Flow Matching生成轨迹。
具体流程:
感知方面上采用transfuser,融合图像和LiDAR信息,得到BEV feature。
通过聚类数据集中的轨迹末端点得到dense的goal point词表,作为goal point的候选集。
将goal point和真实end point的远近程度以及goal point是否在车辆可行驶区域内作为评价标准,从词表中挑选出当前最优的goal point。
引入flow matching对轨迹进行连续建模,将场景信息和goal point作为condition生成轨迹。
实验结果

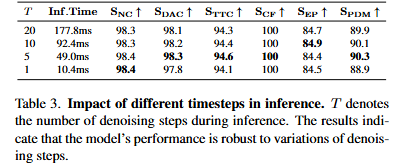
在Navsim数据集上,轨迹采用碰撞率,是否在可行驶区域内,舒适度等综合指标PDMS来评价。GoalFlow在PDMS上达到90.3分,远超以regression为代表的Transfuser方法(84.0分)和naive的generative model(85.6分)。模拟真实场景用更精确goal point代替预测goal point时,PDMS达到92.1分,逼近人类驾驶的94.8分。此外,基于flow matching的方法对推理中denoising步数具有鲁棒性,只需1步推理就能达到优异性能,大大减轻自动驾驶硬件负担。
展望与总结
GoalFlow通过聚类方法捕捉目标点 (goal point) 的分布特性,并设计了一套目标点评估机制,为目标点进行打分。基于这些目标点,GoalFlow引导生成式方法Flow Matching生成高质量轨迹。实验表明,GoalFlow能够生成优异的轨迹,并提供多样化的高质量轨迹候选,显著提升了轨迹生成的性能。
未来,我们将进一步探索如何优化引导信息的利用,尤其是设计更高效的网络结构,以更好地平衡场景信息和目标点引导信息对模型的影响。此外,当前工作主要聚焦于坐标位置作为引导条件,之后可以进一步探索将人类语言指令作为条件输入,结合GoalFlow实现更智能的指令跟随能力,拓展其在人机交互和自动驾驶等领域的应用潜力。
参考文献:
[1] Chen, S., Jiang, B., Gao, H., Liao, B., Xu, Q., Zhang, Q., Huang, C., Liu, W., and Wang, X. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv preprint arXiv:2402.13243, 2024.
[2] Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., and Geiger, A. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. Pattern Analysis and Machine Intelligence (PAMI), 2023.
[3] Jiang, C. “., Cornman, A., Park, C., Sapp, B., Zhou, Y., and Anguelov, D. Motiondiffuser: Controllable multi-agent motion prediction using diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9644–9653, June 2023b.
[4] Yang, B., Su, H., Gkanatsios, N., Ke, T.-W., Jain, A., Schneider, J., and Fragkiadaki, K. Diffusion-es: Gradientfree planning with diffusion for autonomous driving and zero-shot instruction following. arXiv preprint arXiv:2402.06559, 2024.
[5] Sun, W., Lin, X., Shi, Y., Zhang, C., Wu, H., and Zheng, S. Sparsedrive: End-to-end autonomous driving via sparse scene representation. arXiv preprint arXiv:2405.19620, 2024.



 .
.分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


