








CVPR 2025 | UMGen:多模态驾驶场景生成统一框架
2025/03/20


• 论文地址:
https://arxiv.org/abs/2503.14945
• 项目主页:
https://yanhaowu.github.io/UMGen/
概述
端到端自动驾驶技术的快速发展对闭环仿真器提出了迫切需求,而生成式模型为其提供了一种有效的技术架构。然而,现有的驾驶场景生成方法大多侧重于图像模态,忽略了其他关键模态的建模,如地图信息、智能交通参与者等,从而限制了其在真实驾驶场景中的适用性。
为此,我们提出了一种多模态驾驶场景生成框架——UMGen,该框架能够全面预测和生成驾驶场景中的核心元素,包括自车运动、静态环境、智能交通参与者以及图像信息。具体而言,UMGen将场景生成建模为Next-Scene Prediction任务,利用帧间并行自回归与帧内多模态自回归技术,使得一个统一模型即可生成以自车为中心、模态协同一致的驾驶场景序列。UMGen生成的每个场景均包含自车、地图、交通参与者、图像等多种模态信息,并可灵活扩展至更多模态,以适应不同应用需求。
UMGen不仅能够灵活生成多样化的驾驶场景,还支持基于用户设定生成特定驾驶情境,例如控制自车执行左转、右转,或模拟他车cut-in等复杂交互行为。凭借这一交互式生成能力,UMGen可为自动驾驶系统的训练提供稀缺样本,从而提升模型的泛化能力。同时,它还可用于构建闭环仿真环境,对端到端自动驾驶系统进行全面测试与优化,甚至支持自博弈式训练,进一步增强系统的智能决策能力。
UMGen生成的多模态场景,视频中的每一个模态(自车动作,地图,交通参与者,图像)都由模型自行想象生成
方法

Pipeline of UMGen
UMGen从给定的初始场景序列开始,逐场景、自回归地生成多模态驾驶场景。我们首先根据历史信息预测自车要采取的动作,然后根据这一动作预测观察到的地图变化,以及其他交通参与者的行动,最后将这些信息映射到图像中。为实现这一目标,我们将每个时刻的场景元素(包括自车动作、地图、交通参与者以及摄像头图像)转换为有序的token序列,从而将生成任务转化为Next-token Prediction任务。一个很直观的想法是将来自不同帧、不同模态的token直接拼接在一起,然后使用一个decoder-only的transformer进行预测。但是这样做,token数量会随着场景长度的增加而迅速增加,使得算力需求变得无法接受。
为了解决这一问题,我们提出了一种两阶段序列预测方法,将整体任务划分为帧间预测和帧内预测两个阶段。在帧间预测阶段,我们设计了时序自回归模块 (TAR) ,该模块通过因果注意力机制对帧间的时序演化进行建模,确保每个token仅依赖于其历史状态,从而捕捉时间维度上的动态变化。在帧内预测阶段,我们引入了有序自回归模块 (OAR) ,该模块通过指定帧内模态生成的顺序(自车动作→地图元素→交通参与者→摄像头图像,如下视频所示),建立场景内不同模态之间的关联,从而保证模态间的一致性。TAR和OAR模块协同工作,不仅有效捕捉了跨模态的时序依赖关系,还显著降低了计算复杂度,为高效生成多模态驾驶场景提供了技术保障。同时,为了增强自车动作与地图变化之间的模态一致性,我们还提出了AMA模块,根据自车动作计算affine transformation矩阵对地图特征进行变换,充分利用地图这种静态元素的时序先验提升预测精度。
UMGen生成过程可视化
实验及可视化
UMGen在nuPlan数据集上进行训练,并通过可视化和定量实验证明其具备自由幻想多模态驾驶场景的能力,以及按照用户需求生成特定驾驶场景的能力。此外,我们还展示了UMGen在闭环仿真中的应用潜力:通过将自定义的自车动作注入UMGen中替换生成的自车动作,UMGen实时生成了相对应的下一时刻场景。
以下对部分实验结果进行展示。
自由幻想生成驾驶场景序列
由UMGen自主推理生成场景,用户不对UMGen提供任何额外的控制信号。
A. 生成长时序多模态驾驶场景
B. 生成多样驾驶场景
自车受控下的场景生成
用户控制自车动作以生成指定行为模式下的多模态场景。
A. 在路口控制自车直行或者右转
B. 控制自车停车等待或者变道超车
用户指定的场景生成
在此模式下,用户可通过控制指定交通参与者的动作以创造场景。
在该场景中,通过设定黑色汽车的横向速度,我们创造了一个"他车突然变道插入"的危险场景,并控制自车刹车或者变道完成规避。
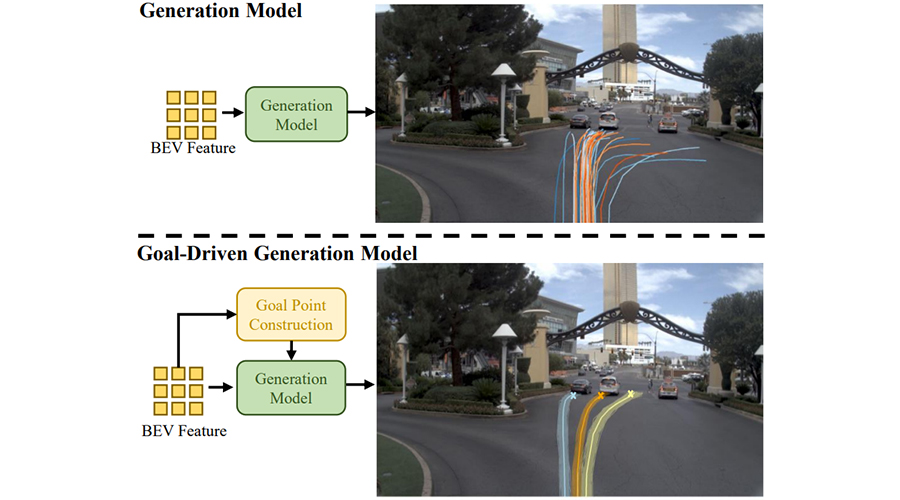
利用Diffusion Model进一步提升图像
质量
受到近期Diffusion模型的启发,我们训练了一个基于transformer的Diffusion模型。通过将UMGen生成的token作为condition,我们实现了更高质量的图像生成。
小图为原始生成图像,大图为Diffusion模型生成图像
总结
UMGen在统一框架内实现了多模态驾驶场景的生成,每个场景包含自车动作、地图、交通参与者以及对应的图像信息。其交互式生成的能力,展现了广泛的应用潜力, 如作为闭环仿真器的核心组件以及corner case数据生成器等。在未来的研究中,将更多模态数据(如激光雷达点云)纳入生成框架中,将是一个值得探索的方向,这有望进一步提升场景生成的丰富性和实用性。
参考文献:
[1] Hu, Yihan, et al. "Solving Motion Planning Tasks with a Scalable Generative Model." arXiv preprint arXiv:2407.02797 (2024). Hu et al. (2024)
[2] Mahjourian, Reza, et al. "UniGen: Unified Modeling of Initial Agent States and Trajectories for Generating Autonomous Driving Scenarios." arXiv preprint arXiv:2405.03807 (2024). Mahjourian et al. (2024)
[3] Hu, Anthony, et al. "Gaia-1: A generative world model for autonomous driving." arXiv preprint arXiv:2309.17080 (2023). Hu et al. (2023)
[4] Sun, Wenchao, et al. "Sparsedrive: End-to-end autonomous driving via sparse scene representation." arXiv preprint arXiv:2405.19620 (2024).

分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


