








开发者说 | HOPE:基于自动驾驶场景Occupancy和Flow的运动预测
2022/07/04

背景
预测任务是自动驾驶场景中至关重要的一项任务,其目的是通过对运动物体的历史轨迹和运动状态的观测,结合道路信息,推测其未来的行为,为下游的规划控制提供更丰富的预测信息。其表征形式通常为多条未来可能的轨迹。近年来,越来越多的研究表明,基于鸟瞰图的空间占有栅格和光流的表征形式相比多条轨迹预测有更强的表征能力。相比于轨迹的形式,占有栅格有更丰富的空间分布信息,能更好的表征动态物体的位置,形状,身份的不确定性;其联合概率分布的形式在一定程度上可以处理物体之间的交互的能力;同时,所有的动态物体可以同时并行处理,极大地提升了处理的效率;另外,此种方法还具有推测被遮挡物体的能力,能有效预防诸如“鬼探头”等的情况;最后,其鸟瞰图下的表征形式能更好地与上下游相结合。基于这个趋势,Waymo于今年推出了全新的自动驾驶挑战赛项目,即Occupancy and Flow Prediction Challenge。此挑战赛给定过去一秒中动态物体(车辆,自行车和行人)的运动轨迹,要求对未来八秒的可观测物体的栅格占有、遮挡物体的栅格占有以及对应光流做预测。本方法结合了CNN、transformer、三维稀疏卷积等优势,利用隐变量丰富了未来的信息,创新性地引入了层级时序解码机制,在此次Waymo挑战赛中取得了极佳的成绩。
方法

输入
编码器一共分为三种,分别是基本编码器,注意力编码器以及时空编码器
基本编码器:作为整个框架的基本编码器,我们选择使用了RegNet[1]模型。RegNet是一个设计完备且效率很高的模型。编码器经过层层降采样编码,生成了5个维度上的特征,对应的尺度分别是输入的1/2,1/4,1/8,1/16和1/32。
注意力编码器:近年来,在检测和分割任务中,SwinTransformer及其升级版SwinTransformerV2[2]取得了很好的结果。基于其独特的局部窗口注意力机制,不仅能很好地编码动态物体和路面间的交互,还大量地减少了网络计算量,因此我们使用了SwinTransformerV2来作为整个网络的注意力编码器。为了可以和基本编码器输出特征的尺度相对应,我们将每个patch的尺寸由4改成了2,由此注意力编码器可以输出和基本编码器尺度相同的5个特征。

时空编码器:为了更好地进行帧间信息交互提取,我们设计了一个3D时空编码器来额外捕捉时间尺度上的信息。因为我们的输入信息在鸟瞰图上有着很高的稀疏度,我们选择使用3D稀疏卷积和子流形稀疏卷积[3]来搭建网络。这样既可以大量地加速3D卷积的计算也可以有效防止稀疏特征在早期过快地膨胀(dilation)。我们对应其他编码器,设计了5阶段网络,其中时间维在2和4阶段进行下采样。针对网络的每个输出特征,我们将时间维和特征维进行合并来使特征降维。

聚合器由两部分组成,在空间尺度上,我们利用BiFPN做多尺度的聚合;在时间尺度上,我们利用隐变量模型来丰富未来的信息。类比于条件变分器,我们在每一个尺度,每一个空间位置都对未来的概率进行建模。在训练阶段,我们基于现在时刻的概率分布做采样。推理阶段,我们直接采用概率分布均值。为了保证预测分布和已观测分布的一致性,我们采用Kullback-Leibler divergence损失函数作为监督信号。
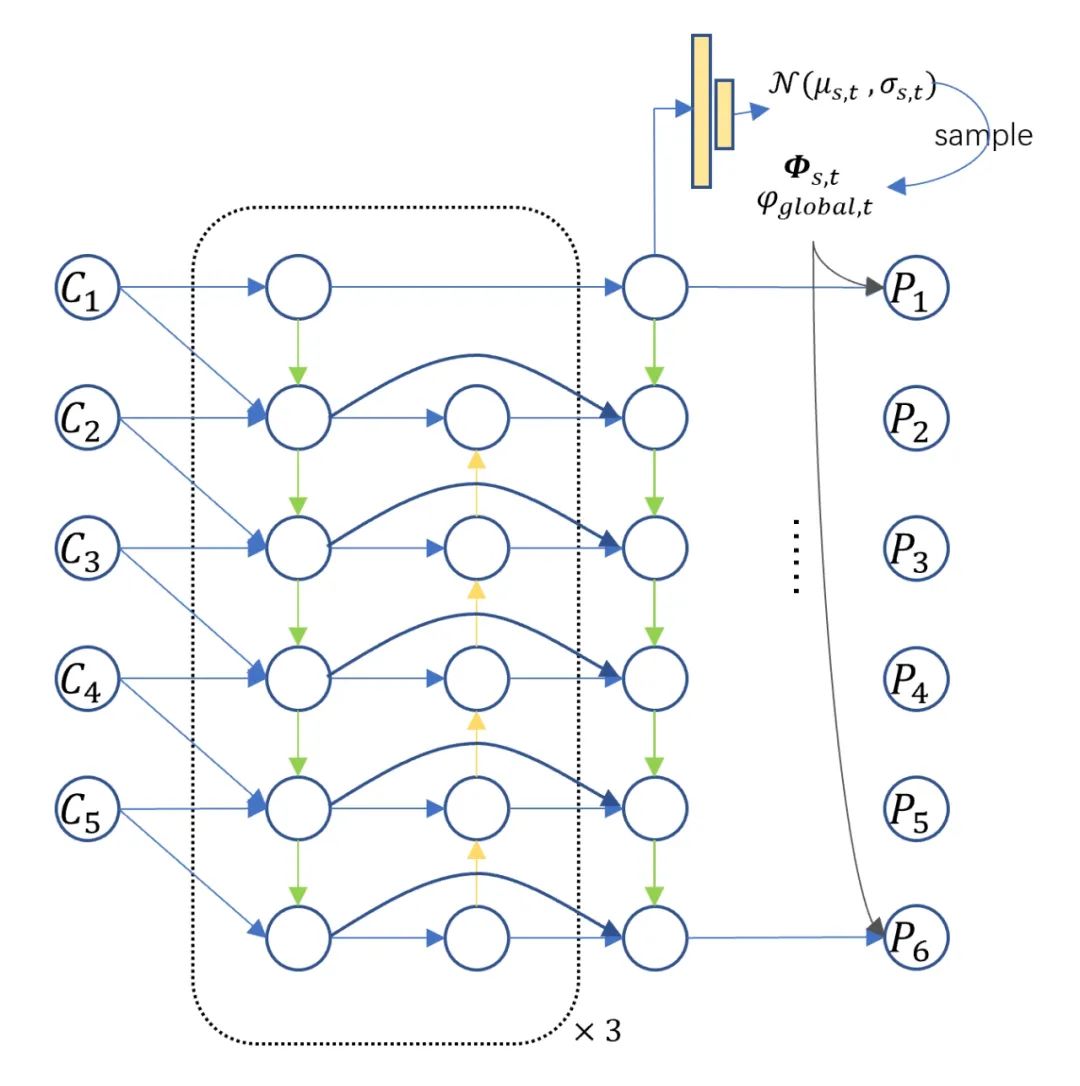
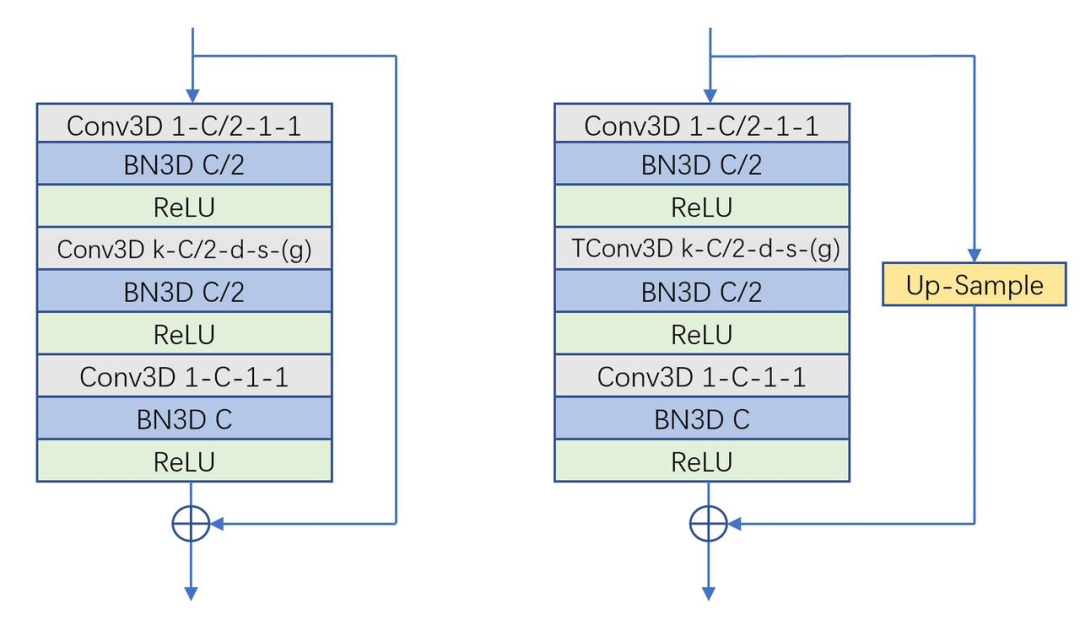
解码器

对于可观测占有栅格和被遮挡占有栅格的预测,我们采用Focal Loss作为其监督信号,两者采用相同的权重进行加权。
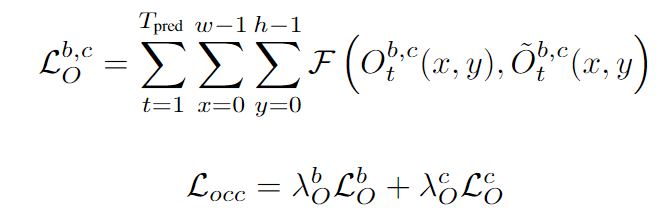
对于光流的预测,我们采用Smooth L1损失函数。为了将光流和占有率的预测解耦,我们利用占有率的真值做加权。

为了保证栅格占有率和光流预测的一致性,我们采用跟踪损失函数进行进一步监督。利用光流的预测,我们可以对前一帧的栅格占有率进行空间变形来得到当前帧的基于光流的空间占有预测。

最后将基于光流的空间占有预测和当前帧栅格占有预测相乘,来得到当前帧的空间占有-光流联合预测,并用此联合预测和当前帧的栅格占有真值来计算损失函数traced loss。我们同时采用Focal loss和交叉熵损失函数进行监督[4]。

为保证聚合器中隐变量中现在和未来的一致性,我们采用Kullback-Leibler divergence损失函数作为监督信号[5]来监督预测的概率分布函数参数。


最后,所有的损失函数进行加权和作为最后的损失函数。

实验结果
消融实验
本表展示了在Waymo数据集上的消融实验结果,灰色的一列为评测的主指标。可以看出,loss的改进,如focal loss和traced loss分别带来了2.01%和0.46%的提升。同时,更丰富的栅格化输入带来了1.23%的提升。同时,结构化的改进,包括隐变量,时空解码器,以及解码器的改进带来了约1.21%的提升。最后TTA带来了约0.40%的提升。值得一提的是,所有的实验都是在十分之一的数据集上做的验证。这些结果充分的说明了我们方法的有效性。

测试集表现
下表展示了我们方法在waymo测试集上的排名,灰色的一列代表评测的主指标,可以看出,我们的结果在主指标上大幅领先对手,充分说明我们方法的优越性。

结果可视化
下面展示我们的方法在特定场景下的对接下来8秒占有栅格(左)和光流(右)的可视化结果。下面列出了直行,红绿灯路口左转右转掉头,无保护左转,4-way-stop,无保护左转,自主避障,停车入库,被遮挡物体的猜测等场景。可以看出,我们的方法能有效地处理复杂场景,能实现多动态物体的交互,交通信息和规则的理解,自主避障,对被遮挡物体的推测等功能。
普通路面:主要展示对不同车速/加速减速情况的车流预测,可以看出HOPE能对未来轨迹的不确定性进行很好的建模
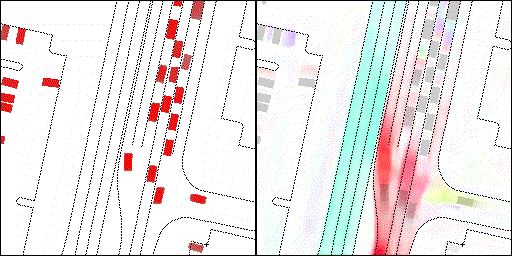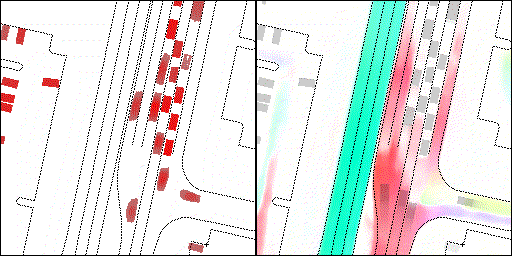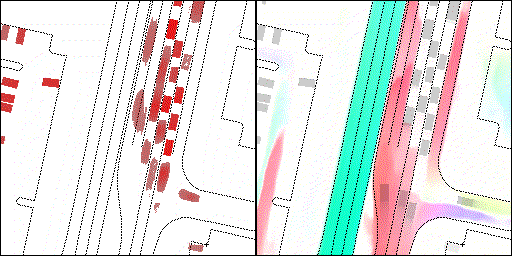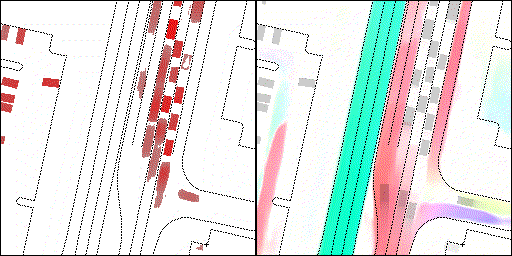
交叉路口:主要展示对不同转弯,停车等待的车流预测

掉头场景:复杂路口

不确定场景:直行、右转两条车道都有可能驶入
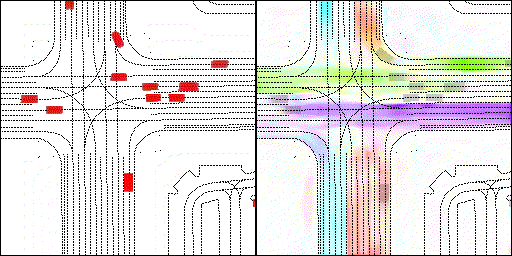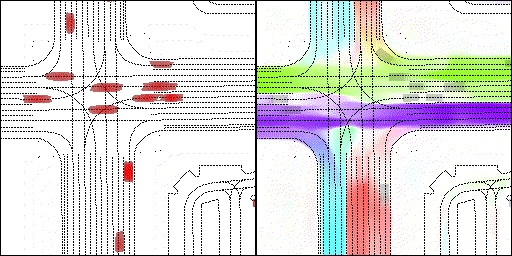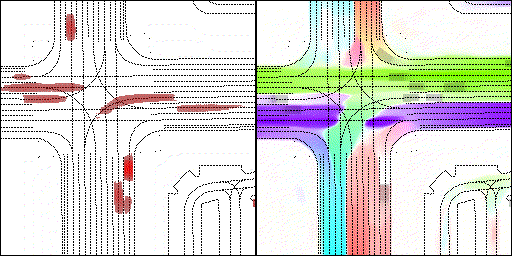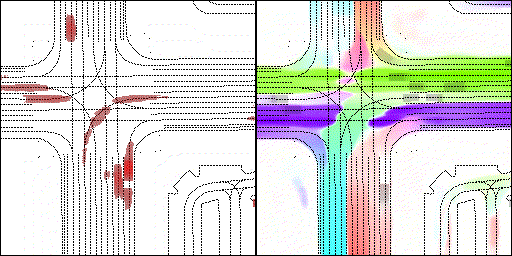
右转:右转车辆对直行车辆进行了避让

左转:根据路口红绿灯、交通规则等综合信息对路权进行判断

无保护左转:左转车辆对直行车辆进行了避让

2 way stop:可以看见车辆交互,处理先来后到顺序

遮挡绕行:可以看见车辆对前方静止车辆进行了绕行

停车入库:小样本、低速场景预测,可以看见低速场景下轨迹的不确定性更高,模型可以有多种可能的轨迹预测

遮挡物体的猜测:绿色的为被遮挡物体

[1]lija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Doll ́ar. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10428–10436, 2020.
[2]Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. arXiv preprint arXiv:2111.09883, 2021.
[3]Benjamin Graham and Laurens van der Maaten. Submanifold sparse convolutional networks. arXiv preprint arXiv:1706.01307, 2017.
[4] Reza Mahjourian, Jinkyu Kim, Yuning Chai, Mingxing Tan, Ben Sapp, and Dragomir Anguelov. Occupancy flow fields for motion forecasting in autonomous driving. IEEE Robotics and Automation Letters, 7(2):5639–5646, 2022
[5] Anthony Hu, Zak Murez, Nikhil Mohan, Sof ́ıa Dudas, Jef-frey Hawke, Vijay Badrinarayanan, Roberto Cipolla, andAlex Kendall. Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15273–15282, 2021
分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


