








CVPR 2023|BoxTeacher: 探索高质量伪标签在弱监督实例分割中的应用
2023/07/28


论文链接:https://arxiv.org/abs/2210.05174
代码链接:https://github.com/hustvl/BoxTeacher
背景
由于实例分割物体级别分割标注成本高,目前一些方法[1,2,3]采用相对成本低的物体框标注与输入图像的先验信息来建模分割标注,如常用的(1)投影约束(2)局部相似性约束。如图1(图截取自[2])所示,其中投影约束限定分割的区域在物体框范围内,保证分割在横向与纵向预测与物体框的范围一致,而未保证框内分割的细节。在此基础上,需要进一步利用图像自身的先验信息来约束分割边界,如图像局部区域色彩信息。在图像局部区域,通常颜色相似的两个像素会被认定为属于同一个物体(或同属于背景),则相应的预测结果也应该具有较高的相似性,这一约束能进一步帮助模型在物体边界做出准确判断。投影约束与局部相似性约束分别从全局定位和局部边界角度实现了实例分割弱标注的建模。

图1:物体框与图像色彩信息建模弱分割标注[2]
目前,基于弱分割标注建模的方法在弱监督实例分割上均取得了不错的突破,如BoxInst在COCO实例分割上能够达到32.1 AP的分割精度(约为全监督85.1%, 基于CondInst-ResNet50),然而这一系列方法与全监督基线仍存在较大的性能差异。在一次偶然的实验尝试中,我们观察到目前这类方法可以输出不少质量不错的分割结果(准确的定位,精细的边界)。如图2所示,对此,我们好奇是否这些质量不错的分割预测是否可以用来降低弱分割标注的学习难度,增强弱监督分割方法的性能。

图2:一些不错的分割预测结果 (由BoxInst-ResNet50生成)
方法
1. Naïve Self-Training
为验证这个想法,我们首先采用最朴素的Self-Training方式进行验证,我们利用训练好的BoxInst直接生成伪标签,并提出基于预测框与标注框的匹配算法(见算法1),实现预测分割与标注框进行匹配,并重新用这些伪分割标注与物体框标注以监督学习的策略训练一个实例分割模型(CondInst),然而最后的结果并不是特别可观,在较短的迭代下,Self-Training的模型性能有微弱的提升(0.3 AP),当迭代延长后,性能提升并不是特别显著,反而相比直接训练3x的BoxInst还要差。针对Naïve Self-Training效果受限,我们分析存在两大问题:(1)没有对低质量的伪标签进行有效的筛选(2)全监督损失对噪声敏感。

图3:Naïve Self-Training模型与结果
2. BoxTeacher
针对以上问题,我们提出了一个端到端的框架BoxTeacher,如图4所示。BoxTeacher采用了Teacher-Student范式,Teacher模型用来生成伪分割标注,对分割进行评分与筛选,并与标注框完成匹配(仅保留高质量的分割),Student模型输入增强后的图像得到分割预测,并与伪标注分割计算分割损失,其包含物体框与图像先验建模的损失以及噪声感知的分割损失。Student模型完成参数更新后,通过Exponential Moving Average(EMA)方式更新Teacher模型。
飞轮效应:当Teacher模型产生不错的分割标注时,Student模型能够取得不错的性能,并传递给Teacher模型,进而促进Teacher模型生成更好的分割标注,使得Student模型进一步得到提升。

图4: BoxTeacher训练框架图
▪ 分割质量评价
为评价分割的质量实现高质量分割的筛选,我们结合物体检测置信度c、物体框约束mb以及分割像素级概率m定义了分割置信度s:

图1:物体框与图像色彩信息建模弱分割标注[2]
▪ 噪声感知的损失函数
考虑到伪标签依旧存在噪声,我们采用分割置信度作为权重调整全监督分割损失:

图1:物体框与图像色彩信息建模弱分割标注[2]
考虑到图像局部区域(3x3区域)中的像素往往具有相似的语义标签,我们利用局部区域像素标注的相似性来进一步降低伪分割标注的噪声,即分割affinity loss。
实验
本文主要以CondInst作为基础分割模型构建BoxTeacher框架,在COCO、PASCAL VOC以及Cityscapes等数据集上训练并测试。如表1所示,BoxTeacher在COCO上取得了不错的精度,如BoxTeacher在ResNet-50和ResNet-101作为主干网络基础下分别达到了35.0 mask AP和36.5 mask AP,相比之前方法BoxInst、BoxLevelSet以及DiscoBox有着显著的提升(+3.0 mask AP),BoxTeacher大幅缩短了弱监督方法与全监督方法的差距,目前BoxTeacher仅依赖于物体框标注可以达到全监督分割方法93.4%的精度。
表2和表3展示了BoxTeacher在PASCAL VOC与Cityscapes上的弱监督分割性能。

表1: COCO实例分割结果

表2&3: BoxTeacher在PASCAL VOC与Cityscapes上的实例分割结果
图5展示了BoxTeacher与BoxInst和self-training方法在不同迭代策略下的对比,在1x训练策略下,BoxTeacher分别取得了1.9 AP与1.6 AP的提升,然而当迭代延长到3x下,BoxTeacher的提升更加显著,相比BoxInst提升了2.4 AP。
表4探究了数据增强对BoxTeacher的性能影响,我们发现,在迭代策略较短情况下(1x),增加数据增强会显著影响全监督与弱监督分割模型,且数据增强对全监督模型负面影响更大。然而,当迭代延长到3x情况下,数据增强会为BoxTeacher带来0.6 mask AP的提升,然而全监督方法依旧没有显著提升。在有噪声监督的训练过程中,采用数据增强能够在Teacher-Student框架下构成一致性约束,提升模型的鲁棒性,缓解噪声标注对模型的影响。
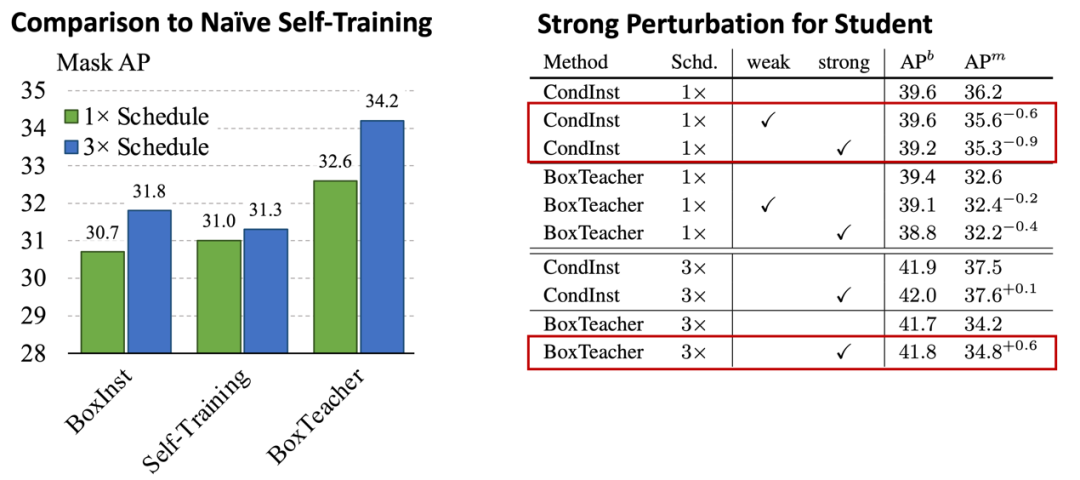
图5: BoxTeacher与BoxInst和self-training的性能对比
表4: 数据增强对BoxTeacher的性能影响
图6展示了BoxTeacher在COCO test-dev上的实例分割可视化结果,BoxTeacher可以产生高质量的分割结果,即使在一些复杂场景也不例外。

图6: BoxTeacher在COCO test-dev上的可视化结果
结论
本文探究高质量伪标签在弱监督实例分割方法的应用并提出了端到端的训练框架BoxTeacher,通过Teacher-Student模型在线生成伪分割标注,并进行筛选与匹配,学生模型利用这些高质量标注完成训练。为充分利用伪分割标注,本文探究了分割置信度来实现分割的评价与筛选,并采用了噪声感知的损失函数来缓解伪分割标注噪声带来的影响。BoxTeacher在COCO、PASCAL VOC以及Cityscapes上都取得了不错的性能提升,缩短了弱监督模型与全监督模型的精度差距。
参考文献:
[1] Cheng-Chun Hsu, Kuang-Jui Hsu, Chung-Chi Tsai, Yen- Yu Lin, and Yung-Yu Chuang. Weakly supervised instance segmentation using the bounding box tightness prior. In NeurIPS,2019.
[2] Zhi Tian, Chunhua Shen, Xinlong Wang, and Hao Chen. Boxinst: High-performance instance segmentation with box annotations. In CVPR, 2021.
[3] Shiyi Lan, Zhiding Yu, Christopher B. Choy, Subhashree Radhakrishnan, Guilin Liu, Yuke Zhu, Larry S. Davis, and Anima Anandkumar. Discobox: Weakly supervised instance segmentation and semantic correspondence from box super- vision. In ICCV, 2021.
分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


