








ICCV 2023|VAD: 基于矢量场景表征的端到端自动驾驶
2023/08/30

nuScenes 开环评测
CARLA闭环仿真

自动驾驶系统通常采用分阶段模块化的设计,即感知、预测、规划等模块相互解耦,独立优化。但对于模块化方案,模块间无法协同优化,存在误差累积,感知的漏检误检将会影响规划的安全性。近年来,端到端自动驾驶逐渐受到业界的关注。端到端方案基于数据驱动的方式优化整个系统,打通了各个模块的壁垒,并减少了繁琐的后处理,具有很高的研究价值。然而,之前的端到端方案往往基于栅格化的环境表征(如图1)。这种密集的表征不具备高层级的语义信息,并且需要较高的计算代价。
在ICCV 2023上,地平线和华中科技大学提出基于矢量化场景表征的端到端自动驾驶算法——VAD。VAD摈弃了栅格化表征,对整个驾驶场景进行矢量化建模(如图2),并利用矢量环境信息对自车规划轨迹进行约束。相比于之前的方案,VAD在规划性能和推理速度上具有明显的优势。VAD的源码已开源,以促进该领域后续的研究。
论文:https://arxiv.org/abs/2303.12077
项目主页:https://github.com/hustvl/VAD

图1 栅格化场景表征

图2 矢量化场景表征
VAD架构:基于Transformer
的端到端模型
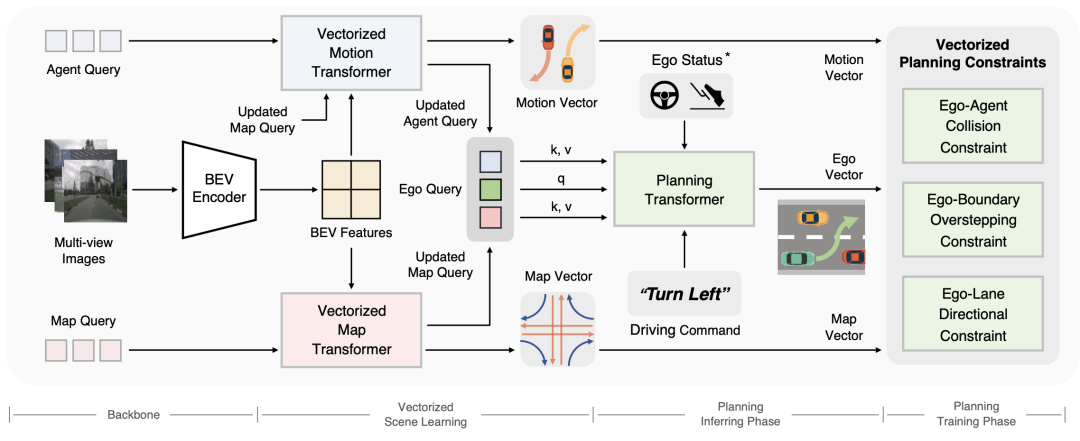
图3 VAD模型框架
VAD基于统一的Transformer结构(如图3所示)。BEV Encoder用于编码输入的环视图像,并将其转化为鸟瞰图视角(BEV)下的特征图;Vectorized Motion Transformer提取场景中的动态目标信息,实现动态目标检测和矢量化的轨迹预测;Vectorized Map Transformer提取场景中矢量化的静态元素信息(如车道线,路沿和人行道);Planning Transformer以隐式的动静态场景特征作为输入,提取其中与驾驶决策规划相关的信息,并完成自动驾驶车辆的轨迹规划。另外在模型训练阶段,VAD基于矢量场景表征,对自车的规划轨迹进行矢量化约束,从而提升规划的安全性。
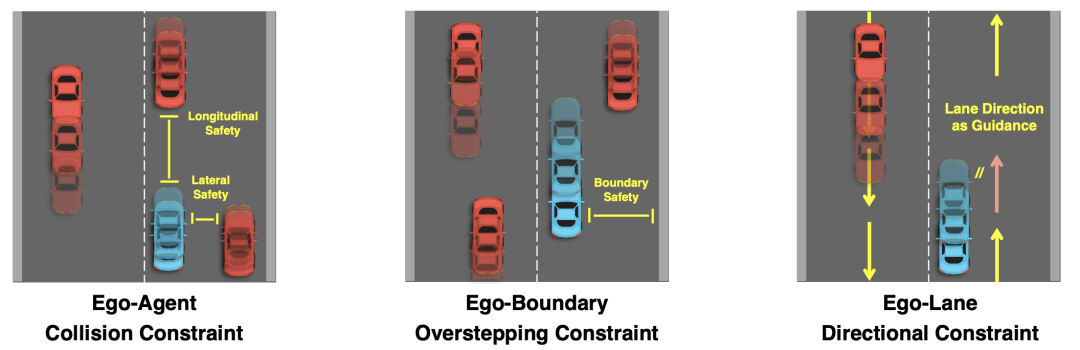
图4 基于矢量场景表征的规划约束
基于矢量场景表征的规划约束
许多先前的工作采用各种后处理策略对规划轨迹进行优化,以提升规划安全性。例如,使用占据图预测结果对规划轨迹进行微调,从而使规划轨迹位于可行驶区域内。这种方法破坏了模型的端到端学习能力,另外,后处理也会带来额外的计算开销,降低模型的推理速度。VAD完全摈弃了后处理策略,而是选择在训练阶段,使用驾驶先验知识优化规划表现,从而在不引入额外推理计算开销的前提下,提升了规划的安全性。
▪ 自车-他车碰撞约束
基于场景中其他动态目标预测的矢量化轨迹和自车规划轨迹的碰撞约束。VAD将自车安全边界分解为横向和纵向的安全距离,当规划轨迹在任一方向与他车预测轨迹的距离小于指定的安全阈值时,则惩罚该轨迹,从而避免自车规划轨迹与他车预测轨迹相交。
▪ 自车-边界越界约束
基于预测的矢量化边界线,VAD约束自车规划轨迹始终在可行驶区域内。当自车规划轨迹越出道路边界线时,则惩罚该轨迹。
▪ 自车-道路方向约束
VAD基于预测的道路线方向,约束自车规划轨迹朝向与道路前进方向保持一致。当自车规划轨迹朝向与道路前进方向有较大差异时,则惩罚该轨迹。
VAD规划性能
VAD在nuScenes开环验证和CARLA闭环验证中均取得了state-of-the-art的规划性能。除此之外,相比之前的方案,VAD大幅提升了模型的推理速度。
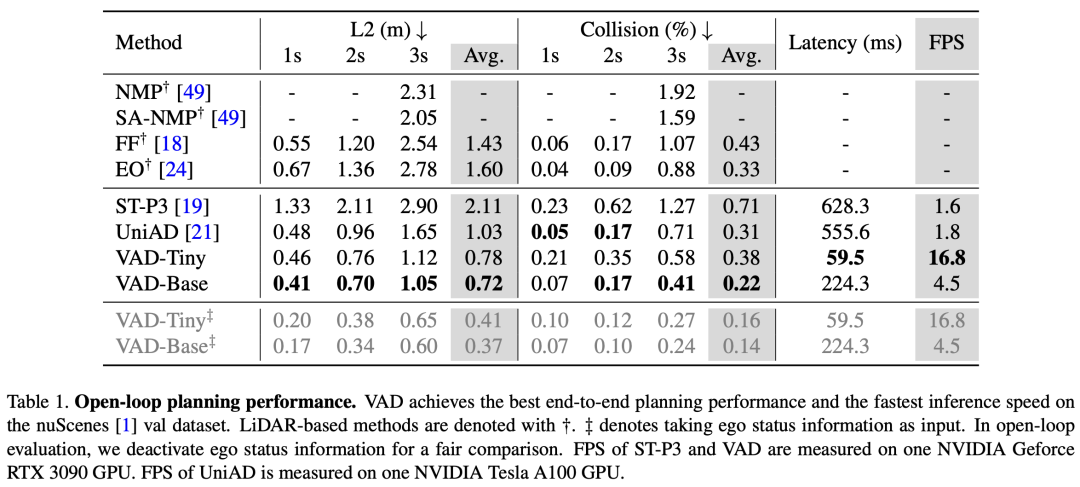
表1 nuScenes开环规划性能
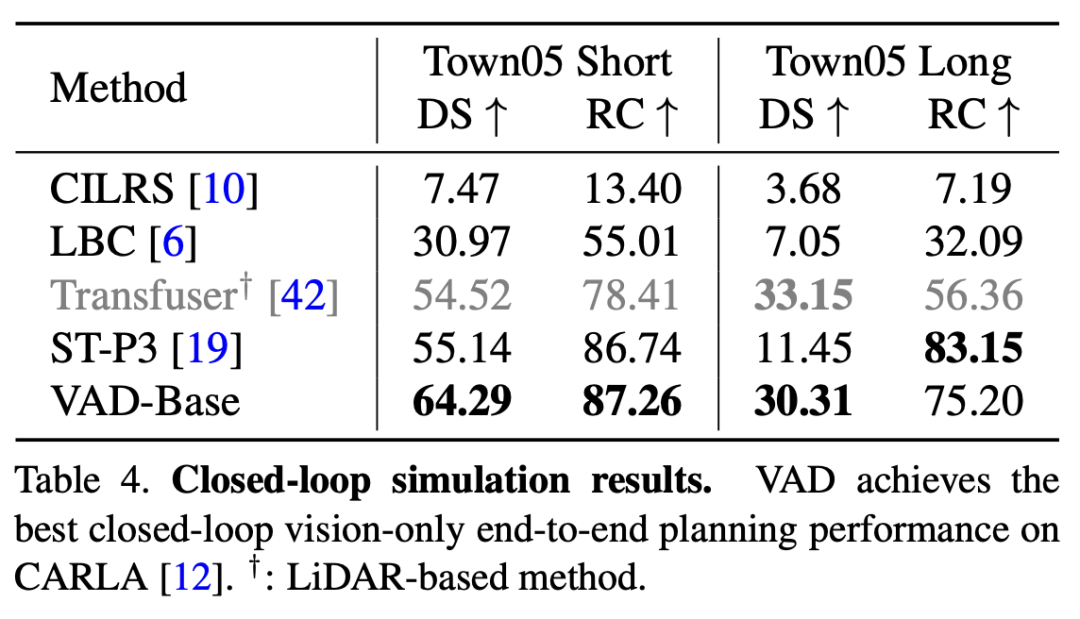
表2 CARLA闭环规划性能
总结与展望
VAD初步探索了基于矢量化场景表征的端到端自动驾驶算法框架。如何将道路拓扑和交通信息融入这一框架中,并进一步提升系统的鲁棒性,将是未来重要的研究方向。
参考文献:
[1] Jiang B, Chen S, Wang X, et al. Perceive, interact, predict: Learning dynamic and static clues for end-to-end motion prediction[J]. arXiv preprint arXiv:2212.02181, 2022.
[2] Liao B, Chen S, Wang X, et al. Maptr: Structured modeling and learning for online vectorized hd map construction. ICLR 2023.
[3] Liao B, Chen S, Zhang Y, et al. MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction[J]. arXiv preprint arXiv:2308.05736, 2023.
[4] Hu Y, Yang J, Chen L, et al. Planning-oriented autonomous driving. CVPR 2023.
[5] Li Z, Wang W, Li H, et al. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. ECCV 2022.
[6] Hu S, Chen L, Wu P, et al. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. ECCV 2022.
[7] Chitta K, Prakash A, Jaeger B, et al. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022..
分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


