








地平线算法工具链新进展! GANet在征程®5上实现高效部署
2023/12/23
地平线征程®5
地平线征程5是专为高阶智能驾驶打造的智能计算方案,搭载地平线第三代架构BPU--贝叶斯(Bayes),算力可达128TOPS,是率先实现前装量产的国产百TOPS级智能计算方案。基于征程5开发的高等级自动驾驶方案可实现ADAS功能、高速导航智能驾驶、城区导航智能驾驶和智慧泊车的全场景覆盖。针对自动驾驶实际工况,Bayes结合突破性的AI加速计算技术,通过灵活配置的访存计算,极大的优化内存占用及访存,将并行计算发挥到极致! |
方案介绍
公版模型

公版GANet模型框架
上图展示了GANet的整体框架。输入前视相机图片,依次经过主干网络(backbone)、自注意力模块(SA)、FPN模块提取图片的多尺度特征后,GANet利用一个关键点头(keypoint head)和一个偏移量头(offset head)来分别预测关键点的置信度图(confidence map)和关键点到车道线起始点的偏移量图(offset map),在推理过程中通过对这二者进行采样和组合,可以将关键点分配到所属的车道线,得到最终的车道线预测结果。LFA作为一个特征增强模块,插入在关键点头之前以帮助关键点预测。接下来的几部分我们将对这两部分展开详细的介绍。
可以分为以下几个部分:
Backbone:公版使用ResX系列对输入的图像做特征提取;
SA:自注意力层(Self-Attention, SA ),以获得丰富的上下文信息;
FPN:采用FPN来提取输入图像的多级视觉表示;
LFA:车道感知特征聚合器(LFA)模块,自适应地从车道上的相邻点收集信息,从而增强每个关键点的局部特征表示;
GANetHead: 利用三个头来预测每个点的置信度,偏移量以及误差补偿;
GANetDecoder: 根据GANetHead的输出,对关键点做筛选和聚类,得到最终的车道线信息;
部署分析与优化
模型部署前,需要对公版模型做分析,分为性能和精度的分析。接下来将从这两个方面来做部署分析以及地平线对各个模块的优化。
性能上
Backbone
公版backbone使用的ResNet系列,地平线发布了针对征程5的硬件特性研发的MixVarGENet模型,其性能表现优异,出于性能的考虑,因此地平线方案中替换ResNet为MixVarGENet,下图为征程5上不同backbone的性能对比。

注:不同版本间性能数据存在较小差异
MixVarGENet主要由MixVarGEBlock结构单元构成。下图为MixVarGEBlock的结构图:

MixVarGEBlock由 head op ,stack ops,downsample layers,fusion layers四个基本模块组成。
head_op和stack_op都是由BasicMixVarGEBlock(如GANet中的mixvarge_f2,mixvarge_f4,mixvarge_f2_gb16)这样的基本单元构成。
BasicMixVarGEBlock结构示意图如下所示:
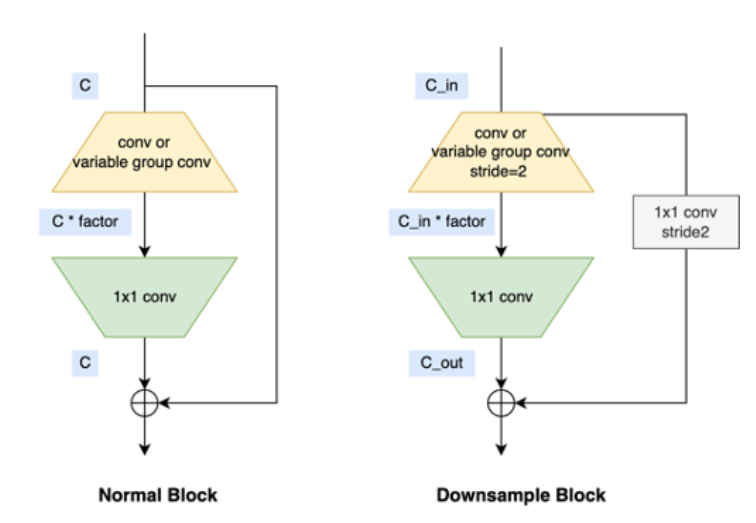
MixVarGENet高度秉承了“软硬结合”的设计理念,针对征程5的算力特性做了一些定制化设计,其设计思路可以总结为:
1. 小channel时使用normal conv,发挥征程5算力优势;
2. 大channel时引入group conv,缓解带宽压力;
3. Block内部扩大channel,提升网络算法性能;
4. 缩短feature复用时间间隔,减少SRAM到DDR访存。
Self-Attention
公版的SA模块其实就是一个self-attention,用于增强特征的全局关联能力。其计算公式为

地平线征程5最早针对的是以CNN为基础的图像处理,但在实践过程中,逐渐衍生出支持语音,Transformer等类型的模型。不过以CNN为基础的模型仍然是效率最高的模型,这一点在编译器内部的体现就是4d-Tensor仍然是最高效的支持方式。因此我们将该模块从传统的三维计算等价修改为四维计算已达到高效支持,同时减少多个reshape和permute操作,保证精度的同时提升推理性能。同时,我们将attention里面的hidden_dim从64降低到16,模块个数从2个减少到1个,经实验对比,对性能提升较大且精度影响较小。
Python# 四维计算self-attentionm_batchsize, _, height, width = x.size()proj_query = self.query_conv(x).view( m_batchsize, 1, -1, height * width)proj_key = self.key_conv(x).permute(0, 2, 3, 1)energy = self.matmul_1.matmul(proj_key, proj_query)energy = energy.view(m_batchsize, -1, height * width)attention = self.softmax(energy)attention = attention.view(m_batchsize, 1, -1, height * width)proj_value = self.value_conv(x).view( m_batchsize, -1, 1, width * height)out = self.matmul_2.matmul(proj_value, attention)out = out.view(m_batchsize, -1, height, width)
LFA
增强车道线的局部连续性,公版模型中使用了一个车道线感知的特征增强模块(LFA),将其插入关键点头之前,从而更好的利用车道线上周边点的特征来增强当前点的特征。

LFA模块的实现由可形变卷积构成,由于征程5上对可形变卷积的支持不太友好,且从论文中看出来,去掉后对精度的影响在可接受的范围内(见下表),因此在我们的方案中,LFA模块被去掉了。

GANetHead
GANetHead利用三个头来预测每个点的置信度,偏移量以及误差补偿,这三个预测头都是由卷积层组成。
其中置信度图预测某个点是否是车道线的关键点,偏移量是预测某个点到起点的偏移量,误差补偿是用来补偿下采样取整后带来的误差。
地平线版本对该部分参考公版实现,无其他改动。
GANetDecoder
GANetDecoder的作用是基于GANetHead输出的置信度图、偏移量和误差补偿来构建车道线。如下图所示:

地平线版本对该部分参考公版实现,无其他改动。
基于以上对对公版模型的改进后,GANet模型在征程5上最终的性能达到双核2431FPS,符合实时性的要求。
精度上
GANet的量化训练,主要是采用horizon_plugin_pytorch的Calibration方式来实现的,通过插入伪量化节点对多个batch的校准数据基于数据分布特征来计算量化系数,从而达到模型的量化。GANet模型无需QAT训练就可以达到和浮点相当的精度。除了量化方式上的优化,地平线对量化不友好的算子支持上也做了优化,下面以SA模块为例,说明地平线如何保障模型的量化精度。
Self-Attention
SA(self-attention)模块中,其操作主要由softmax、matmul、permute、view等算子构成。其中softmax底层为多个算子拼凑实现的(cast、exp、sum、mul等),此类算子对量化是不友好的。为了保证量化的精度,因此SoftMax除了在输入输出端使用int8量化之外,中间的结果均采用int16的量化方法。

softmax算子拆分图
在使用方式上,参考目前地平线提供的QAT量化工具,浮点算子到QAT算子的自动映射。用户只需要定义浮点模型,由QAT工具自动实现浮点和量化算子的映射。因此大部分量化算子的实现方式,用户是不需要感知的,尤其像LayerNorm和SoftMax这种算子的量化方式,工具本身默认提供int16的量化方式,用户只需要正常使用社区的浮点算子即可,而不需要再手动设置QAT相关的配置。
通过对算子支持和量化方式上的优化,GANet模型在征程5上的精度表现最终达到浮点的99%以上(0.7949/0.7872)。
实验结果
1. 实验数据
GANet模型基于CULane数据集训练和验证,模型配置如下:
数据集 | CULane |
Input shape | 1x3x320x800 |
Backbone | MixVarGENet |
Neck | SA+FPN |
其性能和精度表现为:
性能 | latency | 1.099ms |
post-process | 0.96ms | |
fps | 2431 | |
精度 | CulaneF1Score-浮点 | 0.7949 |
CulaneF1Score-定点 | 0.7872 |
2. 车道线检测模型部署通用性建议
• 目前车道线检测算法主流的方法大致分为四种类型,基于分割,基于检测,基于关键点和基于参数曲线。基于分割的方法一般在遮挡情况下效果较差,且需要复杂的后处理聚类;基于检测的方法难以适配形状的多样性,比如曲线;基于参数曲线的方法可以学习整体的车道表示,但精度相对不高;基于关键点的方法兼具灵活性和实时性,构建较好的全局信息情况下可以得到较高的精度,在征程5上建议采用这种方法来做车道线检测模型的部署。
• 选用BPU高效支持的算子替换不支持的算子,例如动态卷积等。
• 尽量避免厚重的后处理(例如复杂的聚类方式),复杂的后处理会导致cpu资源紧张,影响模型整体运行效率。
• backbone可以考虑替换为硬件支持友好的模型,例如EfficientNet、MixVarGENet等。
总结
本文通过对GANet在地平线征程5上量化部署的优化,使得模型在该计算方案上用低于1%的量化精度损失,得到latency为1.099ms的部署性能,同时,通过GANet的部署经验,可以推广到其他模型部署优化,例如包含自注意力的车道线检测模型的部署。
附件

使用文档

参考算法版本发布
分享文章







欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


