








开发者说|RAD:基于3DGS孪生数字世界的端到端强化学习后训练范式
2025/02/24


项目主页:https://hgao-cv.github.io/RAD
论文地址:https://arxiv.org/pdf/2502.13144
概述
受限于算力和数据,大语言模型预训练的scaling law已经趋近于极限。DeepSeek R1 / OpenAI o1 通过强化学习后训练涌现了强大的推理能力,掀起新一轮技术革新。当下主流的端到端智驾模型采用模仿学习训练范式,即从大量的人类驾驶数据中拟合类人的驾驶策略。与大语言模型预训练范式相对应,模仿学习的scaling law也将触及瓶颈,其上限是人类的驾驶水平,难以实现远超人类的高阶自动驾驶。此外,模仿学习天然存在因果混淆和开环闭环差异性两方面的局限性,其下限(安全性和稳定性)也难以保证。我们提出端到端强化学习后训练范式RAD(Reinforced Autonomous Driving),基于3DGS技术构建真实物理世界的孪生数字世界,让端到端模型在数字世界中控制车辆行驶,像人类驾驶员一样不断地与环境交互并获得反馈,基于安全性相关的奖励函数,通过强化学习微调引导模型建模物理世界的因果关系。强化学习和模仿学习天然地互补,在模仿学习scaling law的基础上,强化学习scaling law将进一步拓展端到端智驾模型的能力边界。
模仿学习的局限性:因果混淆与开环闭环差异
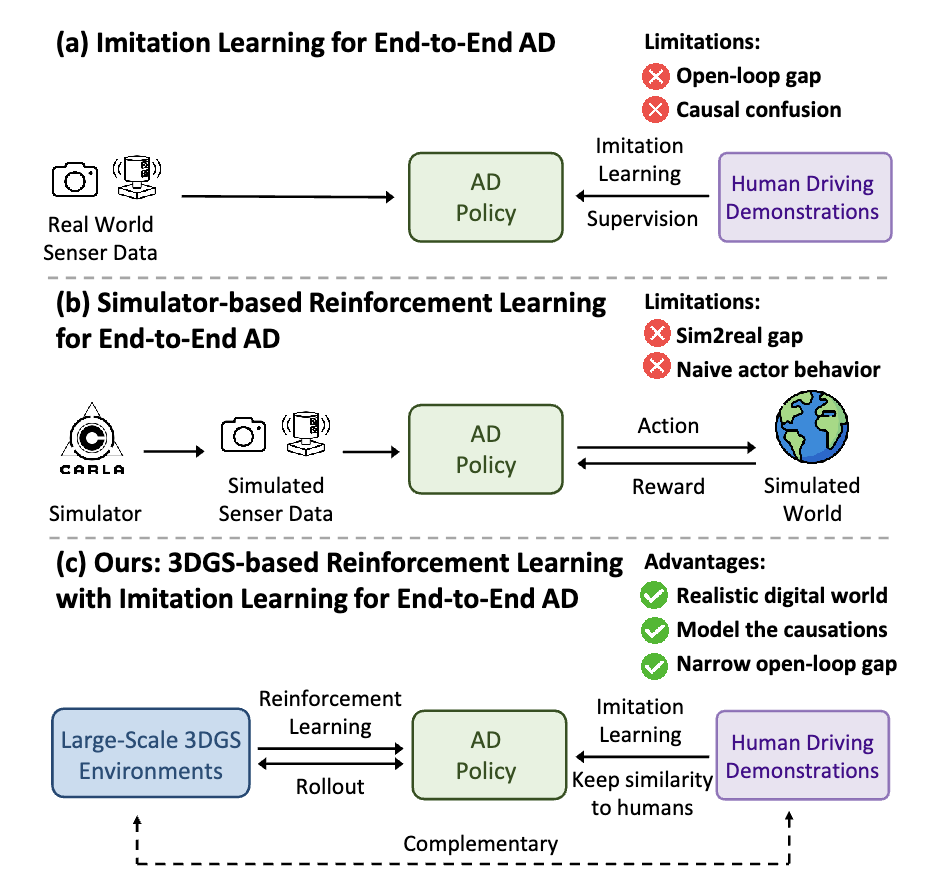
因果混淆(causal confusion)是模仿学习训练范式的一大痛点。模仿学习的本质是使神经网络模仿人类驾驶员的驾驶策略,其优化目标是最小化预测轨迹与专家轨迹之间的差异。模仿学习建模的是环境信息和规划轨迹之间的相关性而非因果关系,容易造成因果混淆的问题。特别是对于端到端自动驾驶而言,输入的环境信息尤为丰富,很难从高维度信息中找出导致规划结果的真实原因,容易导致捷径学习(shortcut learning),例如,从历史轨迹外推未来轨迹。此外,由于训练集主要由常见的驾驶行为主导,在仅使用模仿学习训练的情况下,导致对驾驶的安全性不够敏感。
另外,开环训练和闭环部署之间的差距,也是模仿学习训练范式难以忽视的问题。模仿学习是基于良好的分布内驾驶数据以开环方式进行训练,但真实世界的驾驶系统是一个闭环系统,开环与闭环间存在极大的差异。在闭环中,单步的微小轨迹误差会随时间累积,导致驾驶系统进入一个偏离训练集分布的场景。仅经过开环训练的驾驶策略在面对训练集分布外的场景时往往会失效。
RAD训练范式
RAD基于3DGS技术构建真实物理世界的孪生数字世界,让端到端模型在数字世界中控制车辆行驶,像人类驾驶员一样不断地与环境交互并获得反馈,充分地探索状态空间,学习应对各种复杂和罕见的分布外场景,基于安全性相关的奖励函数,通过强化学习微调让模型对安全性保持敏感,并建模物理世界的因果关系。
(1)三阶段训练架构
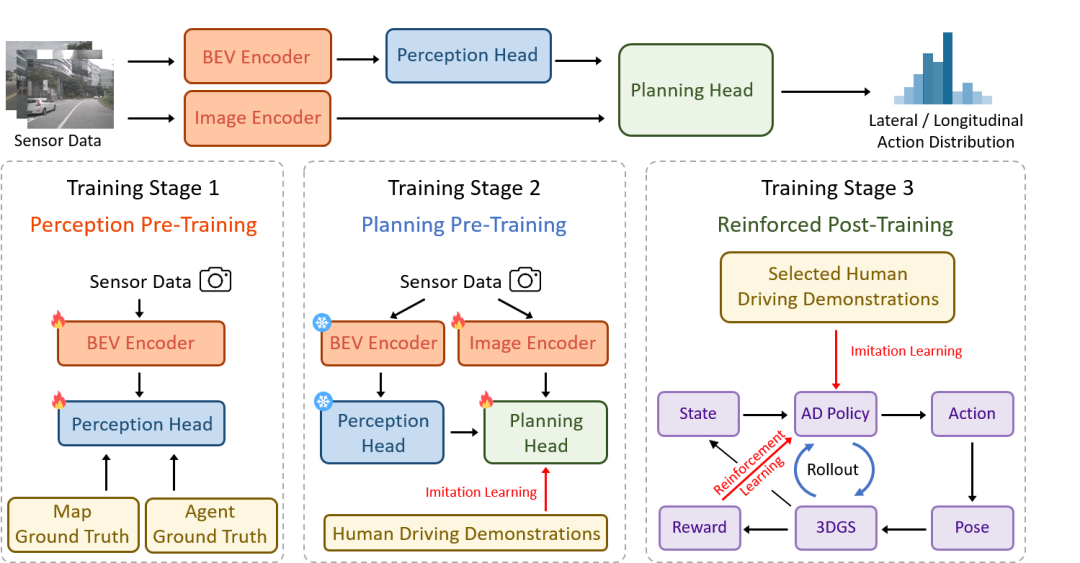
RAD 采用三阶段训练范式。在感知预训练阶段,通过监督学习的方式,训练模型识别驾驶场景的关键元素,建立对周围环境的准确认知;规划预训练阶段,利用大规模的真实世界驾驶示范数据,通过模仿学习来初始化动作的概率分布,避免强化学习训练的冷启动问题;在强化后训练阶段,强化学习和模仿学习协同对策略进行微调。强化学习主要负责引导策略建模物理世界的因果关系和适应分布外的场景;模仿学习作为正则,约束与人类驾驶行为相似性。
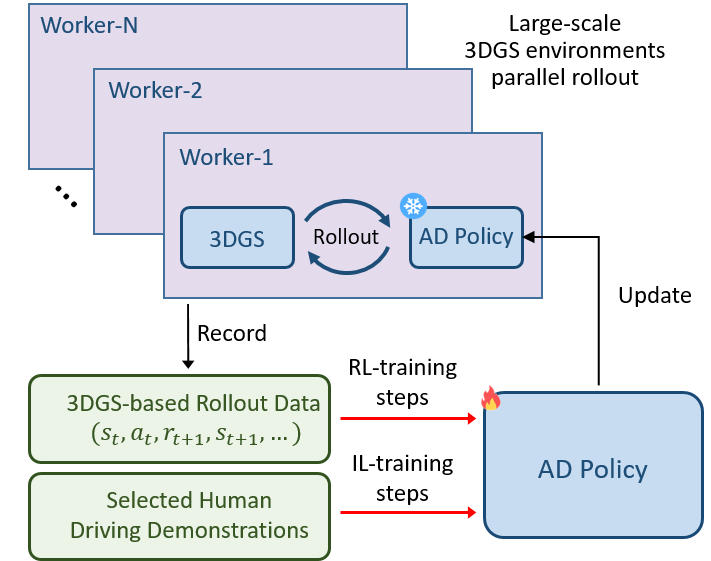
(2)安全导向的奖励函数设计

为了确保自动驾驶汽车在行驶过程中的安全性,RAD 设计了专门的奖励机制。这个机制主要关注四个方面:碰撞动态障碍物、碰撞静态障碍物、与专家轨迹的位置偏差和航向偏差。一旦出现不安全的驾驶行为,比如碰撞或者偏离专家轨迹,就会触发相应的惩罚奖励。通过这种方式,引导策略有效地应对关键安全事件,让自动驾驶汽车在训练过程中逐渐学会如何避免危险,更好地理解现实世界中的因果关系。
(3)策略优化与辅助目标设计
为了提高训练效率和效果,RAD将动作解耦为横向动作和纵向动作,在 0.5 秒的短时间范围内构建动作空间,有效降低了动作空间的维度,加快了训练的收敛速度。此外,在策略优化方面,RAD 使用广义优势估计(GAE)来传播奖励,优化前面步骤的动作分布。考虑到动作空间的解耦,将奖励和价值函数也进行解耦,分别计算横向和纵向的优势估计,并根据近端策略优化(PPO)来微调策略。
同时,针对强化学习中常见的稀疏奖励问题,RAD 引入了辅助目标。这些辅助目标基于动态碰撞、静态碰撞、位置偏差和航向偏差等多种奖励源设计,能够对旧策略选择的动作进行评估,并通过调整动作概率分布来惩罚不良行为。例如,当前方存在潜在碰撞风险时,系统会降低加速动作的概率,并提升减速或制动的概率;当车辆偏离预定轨迹向左偏移时,则增加向右修正方向的动作概率,以减少轨迹偏差。通过这种方式,RAD 为整个动作分布提供密集的指导信息,确保策略能够更快学会安全合理的驾驶行为,从而加速训练的收敛。
闭环验证
RAD 通过基于大规模 3DGS 的强化学习训练,学习到了更有效的驾驶策略。在相同的闭环评估基准测试中,RAD 的碰撞率相较于传统的模仿学习策略降低了 3 倍。这一结果表明,RAD 能在复杂的交通状况下有效避免与动静态障碍物的碰撞,做出更加安全、合理的决策。例如,在遇到突然闯入道路的行人或车辆时,RAD 能够迅速做出准确反应,及时调整车速和行驶方向,避免碰撞事故的发生,而模仿学习策略则可能难以应对这种突发情况。
我们提供了一系列典型场景的闭环结果,以直观展示 RAD 与模仿学习策略在实际驾驶场景中的关键差异:
场景1:绕行;右转
场景2:U形掉头
场景3:跟车蠕行
场景4:无保护左转
场景5:拥挤路口通行
场景6:无保护左转
场景7:绕行;窄道通行
场景8:无保护左转
场景9:跟车行驶
后续工作
RAD作为创新的端到端自动驾驶后训练范式,具有广阔的应用前景和潜力。目前RAD仍存在一些局限性。例如,其他交通参与者的行为是基于场景回放,缺乏交互性的响应;在非刚性物体的渲染、欠观测视角和低光照场景等方面,3DGS的效果还有提升的空间。在后续工作中,我们将进一步提升3DGS孪生数字世界的真实性和交互性,并继续探索强化学习scaling law的上限。
[1] Robert Geirhos, J¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2020. 1
[2] Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph., 42(4):139–1, 2023. 2
[3] Yiren Lu, Justin Fu, George Tucker, Xinlei Pan, Eli Bronstein, Rebecca Roelofs, Benjamin Sapp, Brandyn White, Aleksandra Faust, Shimon Whiteson, Dragomir Anguelov, and Sergey Levine. Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios. In IROS, 2023. 3
[4] Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, and Luc Van Gool. End-to-end urban driving by imitating a reinforcement learning coach. 2021. 3
[5] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017. 5, 6
[6] John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015. 6




分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


