








ECCV 2024|SED:带噪声标签的自适应平衡学习
2024/08/21

深度神经网络(DNNs)凭借其强大的能力,在图像分类、目标检测、语义分割等任务中取得了显著进展。然而,DNNs 的成功依赖于大规模、高质量的人工标注数据集,如 ImageNet(1)。与此同时,获取这些数据集不仅耗时费力,且成本高昂,尤其是需要专业知识的任务(如自动驾驶(2)和医学图像分析(3))。为了降低成本,研究者们转向众包平台(4)和网络图像搜索引擎(5)来获取标签数据,但这些方法通常会导致不可避免的噪声标签问题,从而影响模型的泛化性能(6)。因此,如何在带噪声标签的数据上进行有效学习,成为了当前深度学习领域的一大挑战。

为了应对这一挑战,地平线与合作伙伴在 ECCV 2024 上提出了一种全新的方法——SED(Self-adaptivE and class-balanceD learning):带噪声标签的自适应平衡学习。SED 方法无需依赖数据集相关的先验知识,通过自适应与类别平衡的样本选择和重新加权策略,显著提升了模型在噪声标签数据上的鲁棒性和性能。SED 不仅在理论上提供了创新性的解决方案,还在多个公开数据集上取得了卓越的实验结果。
• 论文链接:
https://arxiv.org/abs/2407.02778
• 项目主页:
https://nust-machine-intelligence-laboratory.github.io/project-SED/
• 开源代码:
https://github.com/NUST-Machine-Intelligence-Laboratory/SED
SED 方法概述
SED 方法的核心在于其三个关键模块:自适应与类别平衡的样本选择(SCS)、自适应与类别平衡的样本重新加权(SCR),以及一致性正则化(CR)。这些模块紧密结合,形成了一个高效的噪声标签处理框架。
“
自适应与类别平衡的样本选择(SCS)
传统的样本选择方法往往依赖于预定义的阈值,这些阈值通常是基于特定数据集的先验知识。然而,这种策略在实际应用中缺乏适应性,难以应对不同的数据集。SED 通过设计一个创新的样本选择策略,在全局和局部阈值的动态更新中实现自适应性和类别平衡。具体而言,SCS 根据输入样本的预测概率来识别干净和噪声样本,确保了每个类别的样本选择都能得到平衡对待,从而避免了模型性能的偏差。
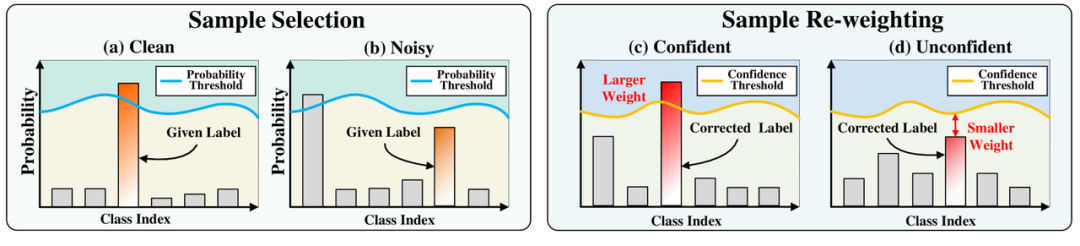
图1:(a-b) 基于预测概率的自适应样本选择,蓝线为类别阈值;(c-d) 基于校正置信度的自适应加权,橙线为类别阈值。
“
自适应与类别平衡的样本重新加权(SCR)
在噪声标签学习中,标签校正后的噪声样本通常被同等对待,忽视了它们在校正置信度上的差异性。SED 引入了一个均值教师模型,通过历史模型的预测生成可靠的伪标签,并根据校正置信度自适应地为这些样本分配不同的权重。SCR 机制有效减轻了由于不平衡标签校正带来的性能下降问题,使得模型在噪声标签数据上的表现更加鲁棒。
“
一致性正则化(CR)
虽然 SED 的样本选择策略已经在很大程度上提高了样本的准确性和平衡性,但不可避免地会有部分噪声样本被错误地选择为干净样本。为此,SED 在这些样本上施加了一致性正则化(CR),通过在弱增强和强增强视图下的样本预测一致性来进一步提升模型的泛化能力和鲁棒性。
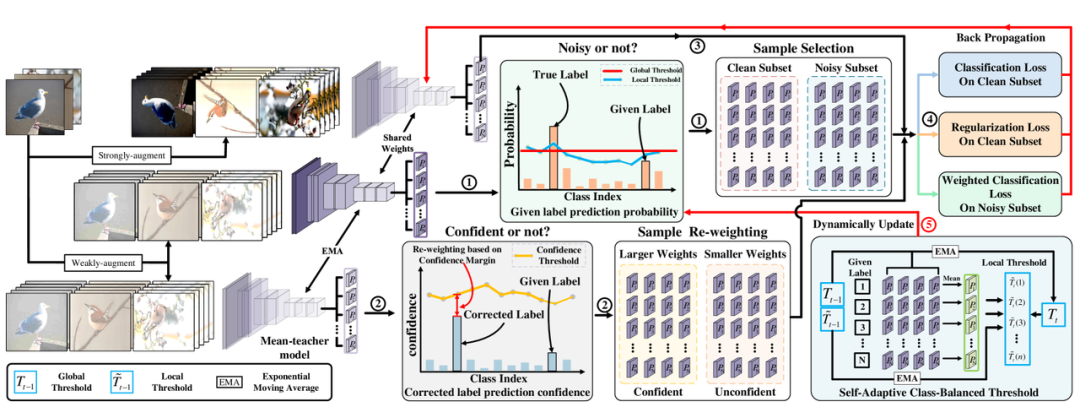
图2:SED 整体框架
SED 根据动态更新的全局和局部阈值,将训练集分为干净和噪声子集。阈值设计实现了样本选择的自适应性和类别平衡。随后,使用均值教师模型校正噪声样本标签,并根据校正置信度自适应分配权重进行训练。最后,对干净样本施加一致性正则化损失,进一步提升模型性能。最终损失整合了分类损失和正则化损失。
实验验证与结果
为了验证 SED 方法的有效性,我们在多个合成数据集和真实世界数据集上进行了广泛的实验。实验结果显示,SED 在处理噪声标签问题上显著优于现有的最先进方法。以下是 SED 在不同数据集上的实验结果和分析:
“
CIFAR100N 和 CIFAR80N 数据集上的实验
在 CIFAR100N 和 CIFAR80N 这两个具有挑战性的合成数据集上,SED 在对称和非对称标签噪声条件下均表现出色。实验结果表明,SED 不仅能够适应不同的噪声场景,还在处理高噪声率的情况下保持了卓越的性能。

表1:实验在对称和非对称标签噪声下进行,†标记表示使用开源代码和默认超参数重新实现。
“
Web-Aircraft、Web-Bird 和 Web-Car 数据集上的实验
在真实世界的 Web-Aircraft、Web-Bird 和 Web-Car 数据集上,SED 也取得了令人瞩目的成果。相比于其他方法,SED 在这三个数据集上的平均测试精度提升了0.94%,显示了其在实际应用中的潜力。

表2:Web-Aircraft、Web-Bird 和 Web-Car 数据集的实验结果。†表示用开源代码和默认参数重新实现。
总结与展望
SED 方法为带噪声标签的学习提供了一种创新性的解决方案,通过自适应和类别平衡的样本选择与重新加权策略,显著提升了模型的鲁棒性和泛化性能。未来,我们期待 SED 在更多场景中的广泛应用,助力各类复杂任务的高效解决。
参考文献:
[1] Deng, J., et al. Imagenet: A large-scale hierarchical image database. CVPR 2009.
[2] Chen, L., et al. End-to-end Autonomous Driving: Challenges and Frontiers. IEEE TPAMI 2024.
[3] Wu, T., et al. Meta segmentation network for ultra-resolution medical images. IJCAI 2020.
[4] Welinder, P., et al. The multidimensional wisdom of crowds. NeurIPS 2010.
[5] Fergus, R., et al. Learning object categories from internet image searches. Proc. IEEE 2010.
[6] Zhang, C., et al. Understanding deep learning requires rethinking generalization. ICLR 2017..
分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱


