








ECCV 2024|KTSE:基于知识传递的弱监督语义分割
2024/08/19

语义分割在自动驾驶等领域的广泛应用中扮演着至关重要的角色(1)(2)。然而,传统的语义分割模型往往依赖大量的像素级标注数据(3)(4)(5),这不仅耗时费力,还限制了模型在大规模应用中的可行性。在弱监督语义分割(WSSS)领域,研究者们一直在寻求更高效的方法来减少标注需求,但现有的方法常常面临过度扩展和欠激活的问题(6)(7),严重影响了目标的精准定位(8)。

为了解决这些挑战,地平线与合作伙伴在 ECCV 2024 上提出了一种全新的弱监督语义分割方法——KTSE(Knowledge Transfer with Simulated Inter-Image Erasing): 通过模拟图像间擦除实现知识传递的弱监督语义分割。KTSE 通过引入额外的目标信息与模拟图像间擦除的过程,显著提升了网络的目标定位能力,避免了传统方法中常见的过度扩展问题(9)。KTSE 不仅在理论上提供了创新性的解决方案,还在多个公开数据集上取得了卓越的实验结果。
• 论文链接:
https://arxiv.org/abs/2407.02768
• 项目主页:
https://nust-machine-intelligence-laboratory.github.io/project-KTSE/
• 开源代码:
https://github.com/NUST-Machine-Intelligence-Laboratory/KTSE
KTSE 方法概述
KTSE 方法由三个核心模块组成:模拟图像间擦除(SIE)、自监督正则化(SSR)和多粒度对齐(MGA)。这些模块紧密结合,形成了一个高效的弱监督语义分割流程。
“
模拟图像间擦除(SIE)
传统的擦除方法通过去除图像中最具辨识度的部分,迫使网络激活其他区域。然而,这种策略容易导致目标区域的过度扩展或不足。KTSE 的 SIE 模块通过引入来自配对图像的额外物体信息,模拟图像间擦除,削弱原始图像的激活,从而避免过度扩展问题,并加强目标区域的完整性。

图1:(a)之前的对抗擦除方法容易导致过度扩;(b)我们通过添加配对图像的对象知识,削弱当前激活,从而增强网络的定位能力;(c)结果对比。
具体来说,SIE 通过引入配对图像中的额外目标知识,削弱当前图像中的目标激活。随后,网络通过从锚点图像中学习对象知识,增强目标定位能力。该方法有效避免了以往基于对抗擦除方法中常见的过度扩展问题,确保了网络能够更准确地识别和定位图像中的目标。
“
自监督正则化(SSR)
KTSE 还引入了自监督正则化模块,旨在确保锚点图像中关键区域的可靠激活。在双向对齐过程中,SSR 模块通过自监督方式引导网络识别复杂图像中的类间边界,从而防止锚点激活的减弱问题。SSR 模块的设计进一步提升了 KTSE 在处理多目标图像时的分割精度。
“
多粒度对齐(MGA)
为了解决传统方法中目标激活区域不足的问题,KTSE 提出了多粒度对齐模块。MGA 通过温和的激活扩展,有效扩大目标区域,同时减少背景噪声的引入。通过增强目标信息的传递,MGA 显著提高了整体分割精度,使 KTSE 在各种场景下都能表现出色。

图2:我们设计的架构包括模拟图像间擦除(SIE)场景,通过配对图像引入额外对象信息,并通过锚点图像学习增强定位能力。自监督正则化(SSR)模块防止双向对齐削弱锚点激活,提升边界识别。多粒度对齐(MGA)模块温和扩大对象激活,促进知识传递。
实验验证与结果
实验结果显示,KTSE 方法在 PASCAL VOC 2012 和 COCO 数据集上的伪掩码准确性和分割结果方面取得了显著的优势。以下是对不同方法的表现进行的定性和定量比较:
“
PASCAL VOC 2012 训练集上的示例定位图
在 PASCAL VOC 2012 训练集上,我们展示了不同方法生成的示例定位图。结果表明,随着我们的方法逐步增强,生成的定位图在目标的完整性和准确性上得到了显著改善。

图3:对于每张 (a) 图片,我们展示了 (b) 标注的真实值,(c) 之前AEFT方法生成的定位图,(d) 我们的基线模型,(e) 基线模型加SIE,(f) 基线模型加SIE和SSR,以及 (g) 基线模型加SIE、SSR和MGA。
“
PASCAL VOC 2012 数据集上的伪掩码准确性和分割结果定量比较
在 PASCAL VOC 2012 数据集上,KTSE 方法在提升伪掩码质量和分割精度方面表现卓越(表1、表2)。这些结果凸显了 KTSE 方法在改进伪掩码质量和提高分割准确性方面的有效性。

“
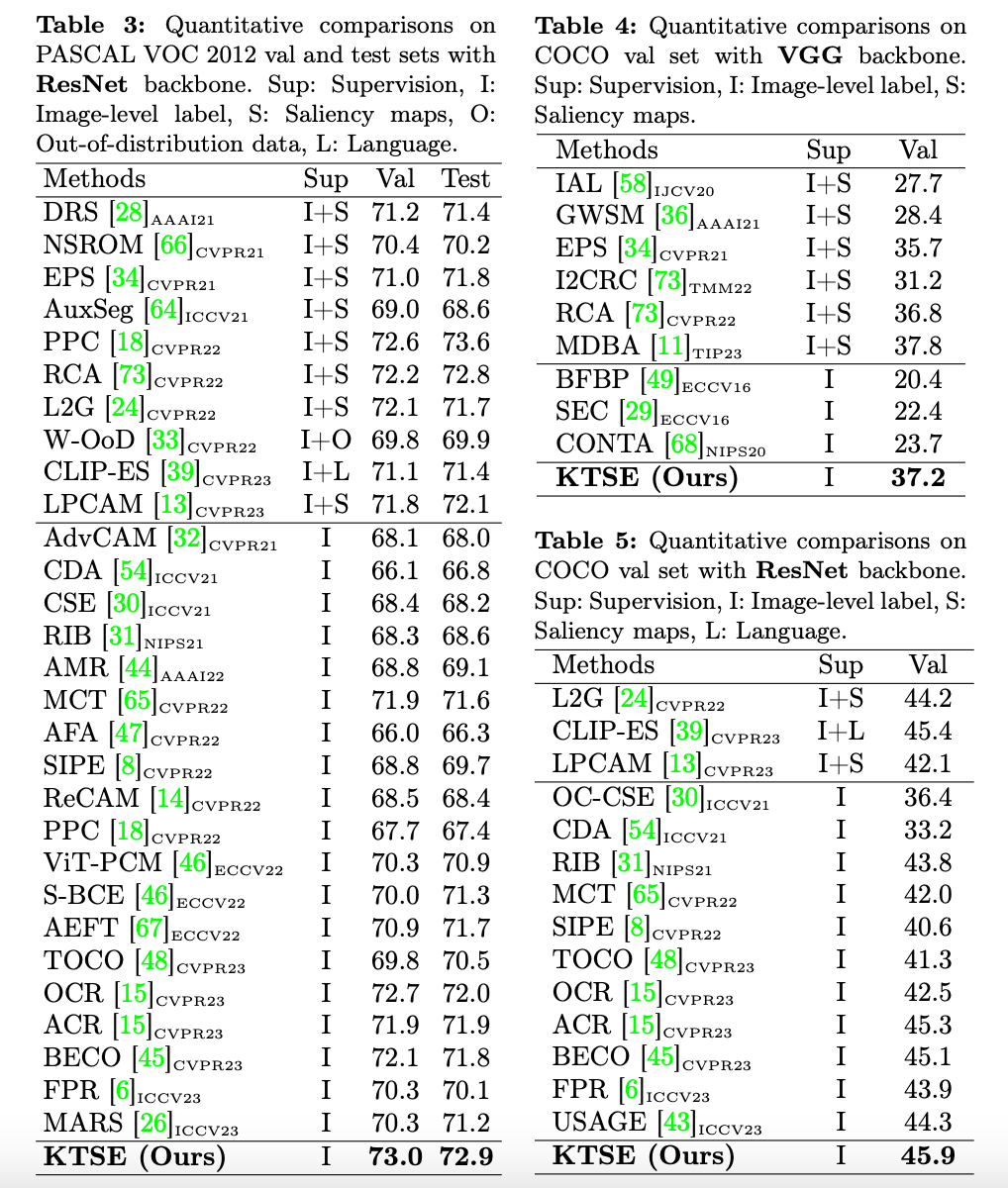
PASCAL VOC 2012 和 COCO 数据集上的分割性能定量比较
在 PASCAL VOC 2012 和 COCO 数据集上,KTSE 方法使用 ResNet 作为骨干网络时,表现出优异的分割性能(表3、表4和表5)。这些表格展示了 KTSE 方法在多个数据集上的出色表现,证明了其在实现更高分割精度方面的优势。
总结与展望
KTSE 方法为弱监督语义分割提供了一种全新的解决方案,通过知识传递与模拟图像间擦除,克服了传统方法中的过扩展和欠激活问题。未来,我们期待这一创新方法能够在更多场景中得到推广,助力自动驾驶等技术的发展。
参考文献:
[1] Long, J., Shelhamer, E., Darrell, T. Fully convolutional networks for semantic segmentation. CVPR 2015.
[2] Chen, L.C., et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE TPAMI 2017.
[3] Bearman, A., et al. What’s the point: Semantic segmentation with point supervision. ECCV 2016.
[4] Dai, J., He, K., Sun, J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. ICCV 2015.
[5] Chen, T., et al. Semantically meaningful class prototype learning for one-shot image segmentation. IEEE TMM 2021.
[6] Zhou, B., et al. Learning deep features for discriminative localization. CVPR 2016.
[7] Wei, Y., et al. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. CVPR 2017.
[8] Zhang, X., et al. Adversarial complementary learning for weakly supervised object localization. CVPR 2018.
[9] Yoon, S.H., et al. Adversarial erasing framework via triplet with gated pyramid pooling layer for weakly supervised semantic segmentation. ECCV 2022.
分享文章





欢迎订阅地平线相关资讯,您可以随时取消订阅。

感谢您的订阅, 我们会第一时间推送地平线最新活动与资讯到您邮箱




